Lecture 13 Linking
today
- Linking
- Library interpositioning 库打桩
Linking
从两个c program 实例开始

想要编译两个模块会发生什么?
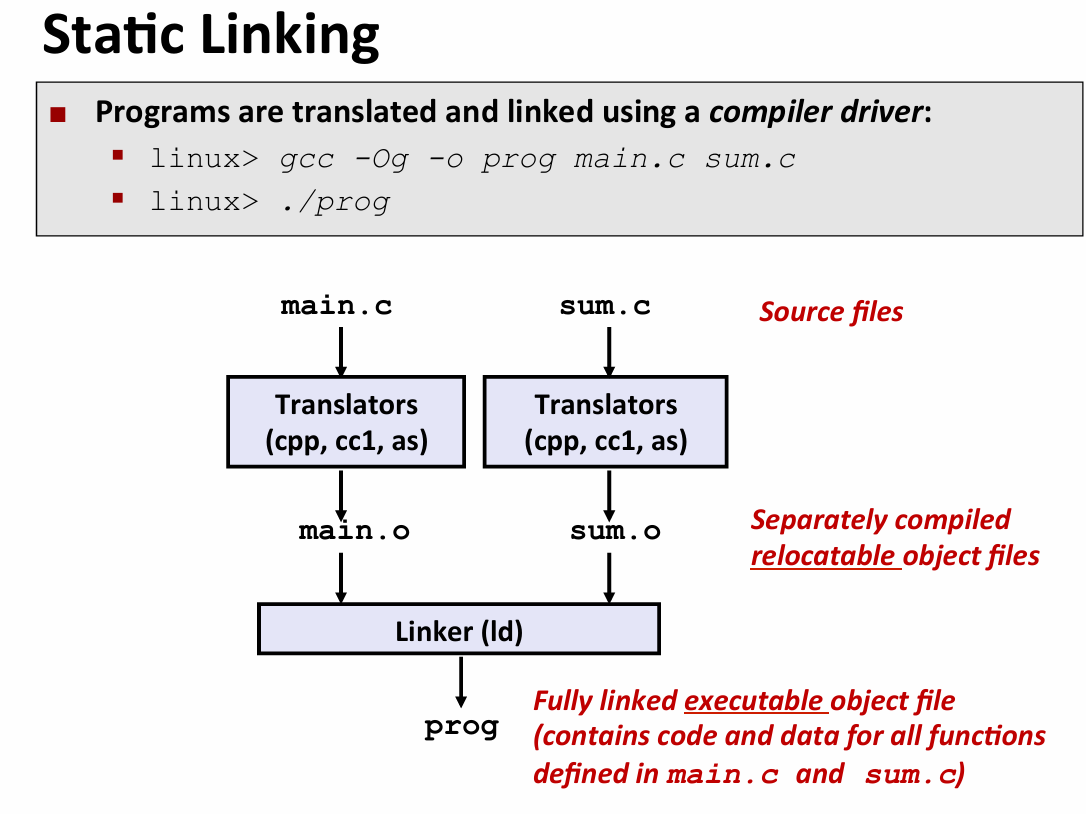
分别对main.c 和 sum.c 进行预处理和汇编 -- 生成.o文件
然后Linker会把所有的文件链接拼凑到一起 -- 包括C Library standard中的文件 生成一个可执行文件
.c 文件叫做 source files(源文件)
.o 文件 叫做 relocatable object files(可重定位目标文件)
最后生成的 -- executable object file(可执行目标文件)
Why Linkers?
Reason 1: Modularity
模块化 -- 分解成更小的部分
Reason 2: Efficiency
效率
更改代码的时候只需要更改其中一小部分 -- 没有必要重新编译其他模块
common function(公共函数) -- 可以聚集到一个文件中 -- 可执行文件和正在执行的内存映像只包含他们实际使用的函数代码
我们编码的时候 实际上只使用了 C的一部分功能和函数 所以没必要把所有的都linker进去 Link 一部分就可以了
What Do Linkers Do?
Step1: Symbol resolution
programs define and reference symbols.
symbol 事实上就是 一些global variable(全局变量)和functions(函数)
eg.
void swap(){} 这是定义symbol swap
swap() 这是在引用symbol swap
int *xp = &x; 这其实是定义了一个xp 引用的是x
assembler(汇编器)将符号定义存储在symbol table中
symbol table is an array of structs.
每个struct中有关于该符号的信息 name, size, and location of symbol.
在symbol resolution过程中 -- 每一个符号引用和每一个符号会相关联
这里可能涉及到在多个模块的符号命名相同等问题……linker需要做出决定
Steps2: Relocation
在编译器和汇编器生成的文件中 在他们眼里 内存是开始于0的 文件中的内存引用仅仅是在这个文件中的偏移量
而linker的工作就是把这些符号的定义 决定它真正加载在哪里 拿到它真正加载在内存中的地址 然后给引用 做出修正
这个真正的地址 -- 是虚拟内存中的位置
跑一下两个.o objump 一下就懂了
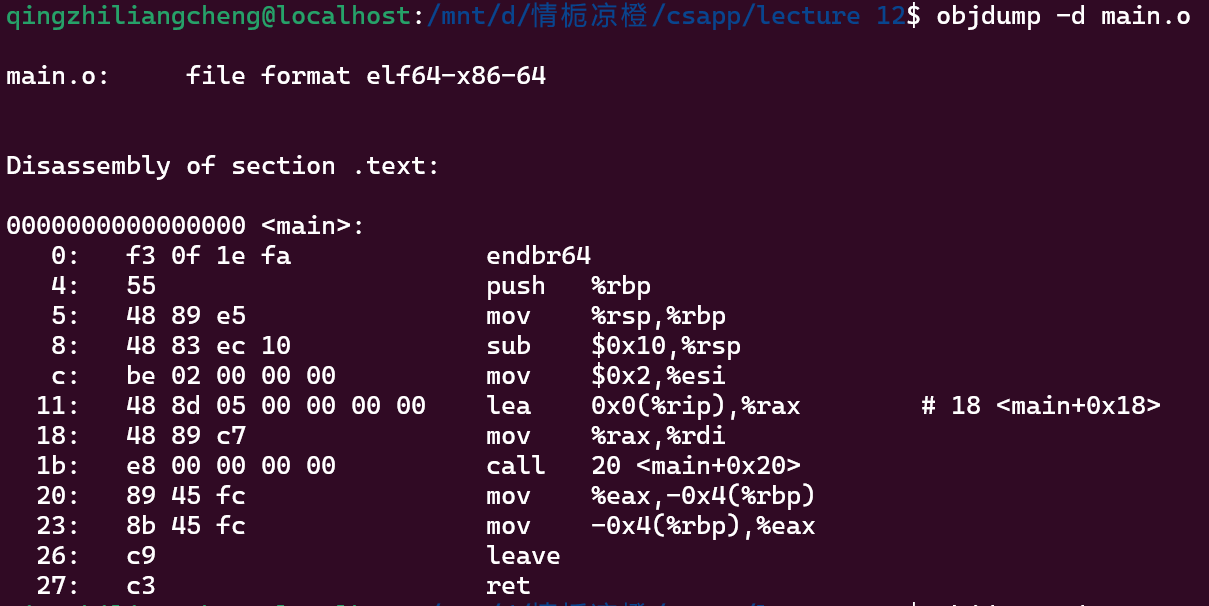
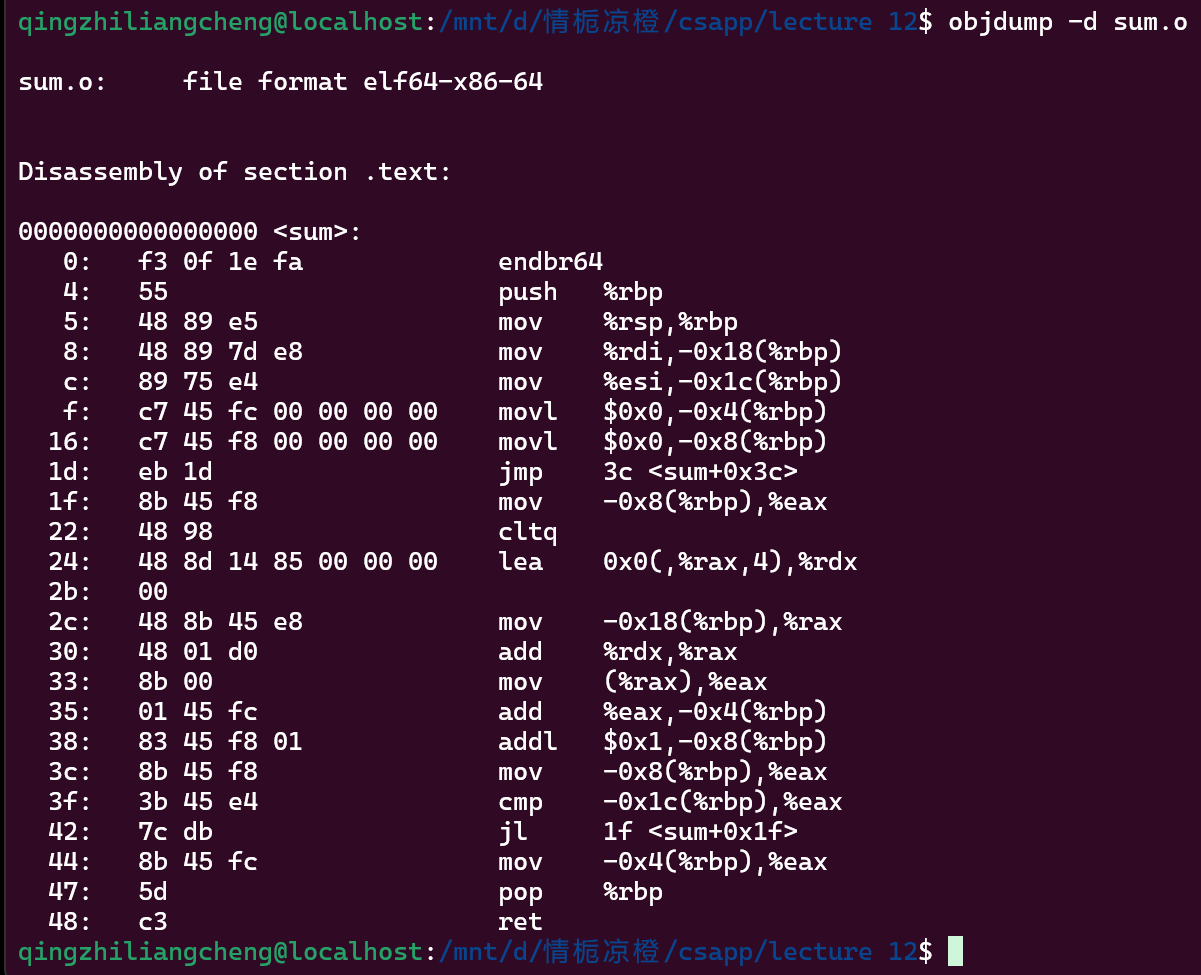
都是从00000开始的 然后.o中只是表明了对于000的偏移量
在linker的时候要换成真正程序在虚拟内存中的内存地址
Three Kinds of Object Files(Modules)
- Relocatable object file(.o file)
- Shared object file(.so file)
Executable object file(a.out file)
其中比较特殊的是 Shared object file 是一种特殊的relocatable object file 可以动态的加载到内存中 然后 连接
总结来说 object file(目标文件) 就是一个文件形式 存储在磁盘的object module(目标模块)
而object module 就是一串字节
但这串字节 有一定的规范
在Linux遵循规范实现的object file 我们称之为 ELF
Executable and Linkable Format(ELF)
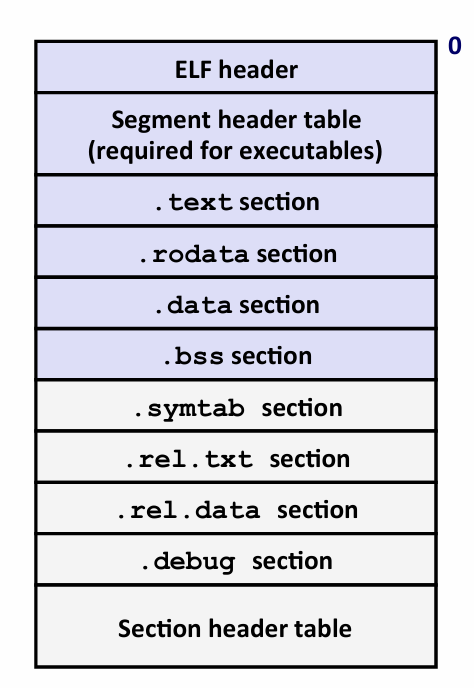
ELF header
我这里写了个小demo 跑了一下ELF header 看了一下里面都有什么
我用的是上面的sum.c 和 main.c 的例子 我把两个文件放到下面的地址了
cd "/mnt/d/情栀凉橙/csapp/lecture 12"
gcc -Og -o prog main.c sum.c
readelf -h prog
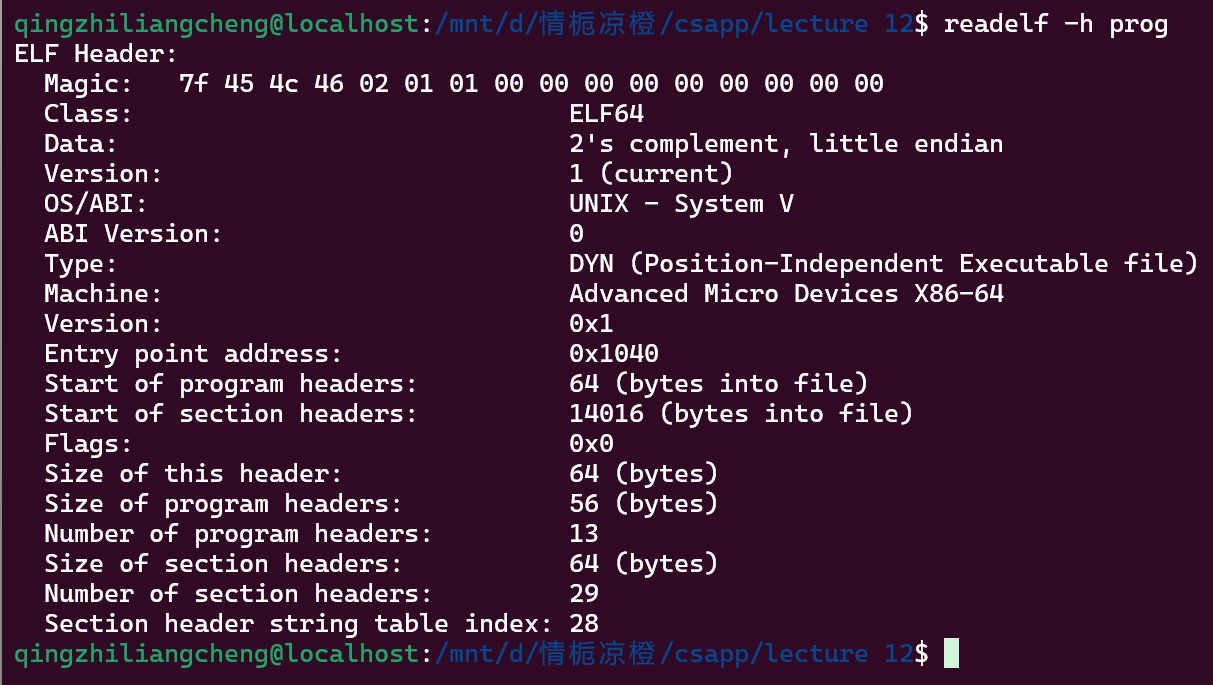
- Magic: 表示是一个ELF文件 -- 这是固定的64位 都是这串字符
- Class: 表示是32位还是64位
- Data: 数据编码方式 大端法/小端法
- Type: 文件类型
- EXEC 可执行文件
- DYN 共享库
- REL 重定位文件
- Machine: 机器架构
Entry point address: 程序入口地址
这个地址就是程序启动时首先用到的地址
比如如果objdump一下
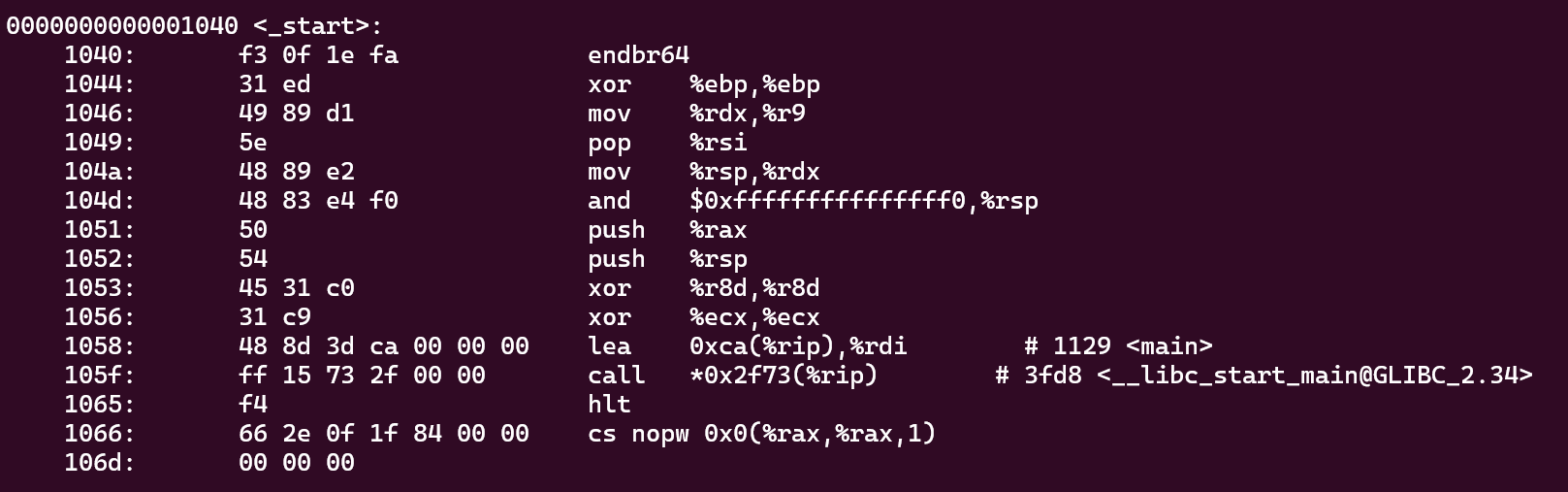
这个地址是个虚拟地址
- Start of program headers, Start of section header: program header 和 section header 在文件中的偏移量
Segment header table
段头部表 -- 只在可执行目标文件中被定义
指出代码的不同段在内存中的位置
栈 共享库 初始化的数据 在哪里
readelf -l prog
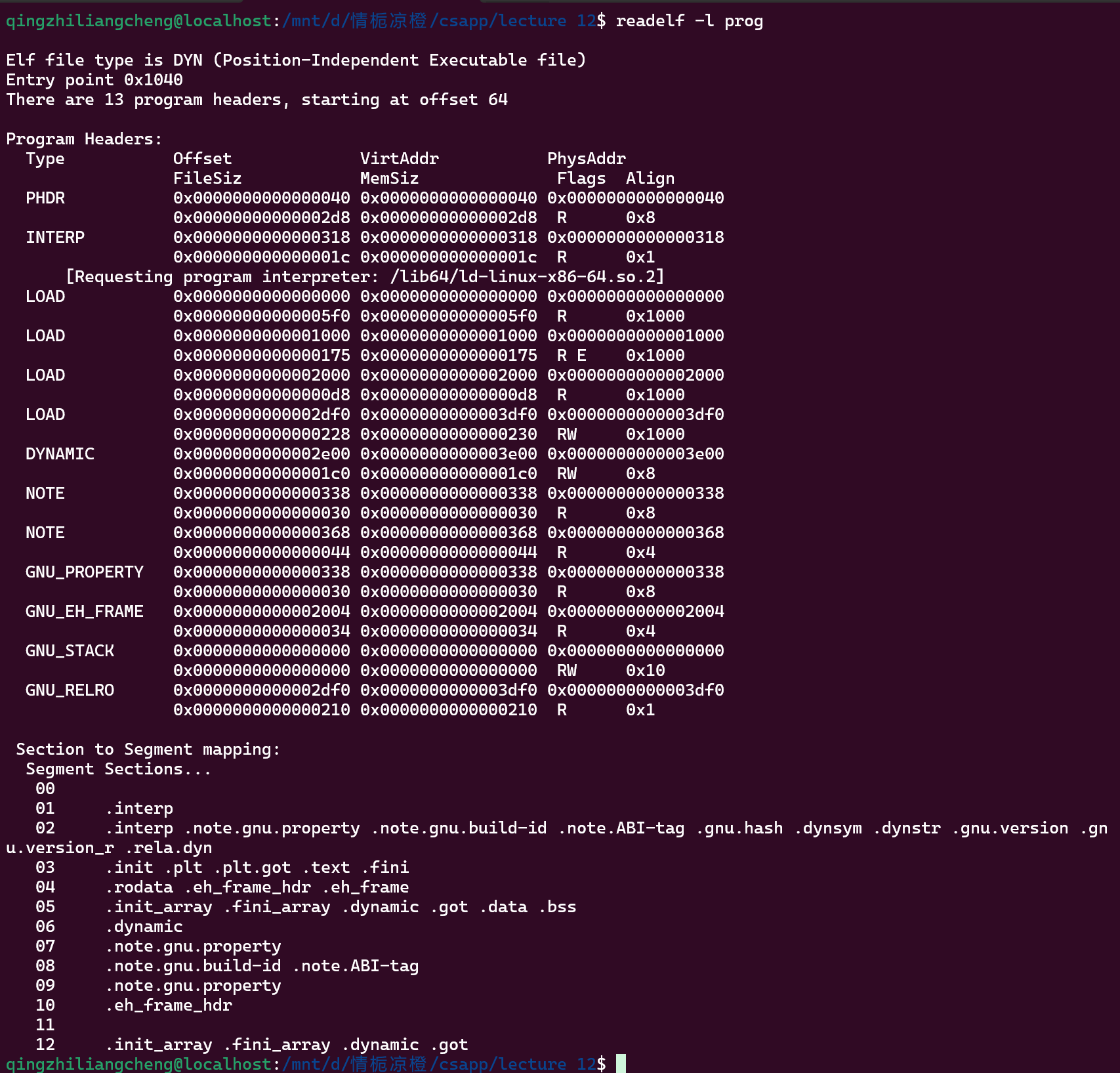
最前面的信息是说了入口地址
还有有13个段
program headers
- Type: 段的类型,描述段的用途。常见类型包括:
PHDR: 描述程序头表本身的段。INTERP: 包含动态链接器路径的段。LOAD: 需要加载到内存的段。DYNAMIC: 包含动态链接信息的段。NOTE: 包含注释信息的段。GNU_STACK: 栈段。GNU_RELRO: 只读重定位段。
- Offset: 段在文件中的偏移量。
- VirtAddr: 段在虚拟内存中的起始地址。
- PhysAddr: 段在物理内存中的起始地址(通常与虚拟地址相同)。
- FileSiz: 段在文件中的大小。
- MemSiz: 段在内存中的大小(可能比文件中的大小大,比如 BSS 段)。
- Flags: 段的权限标志:
R: 可读W: 可写E: 可执行
- Align: 段的对齐要求(必须是 2 的幂次方)。
Section header
这个表告诉你不同section的起始位置
注意在图中 section header是在最下面
readelf -S prog
s一定得用大写
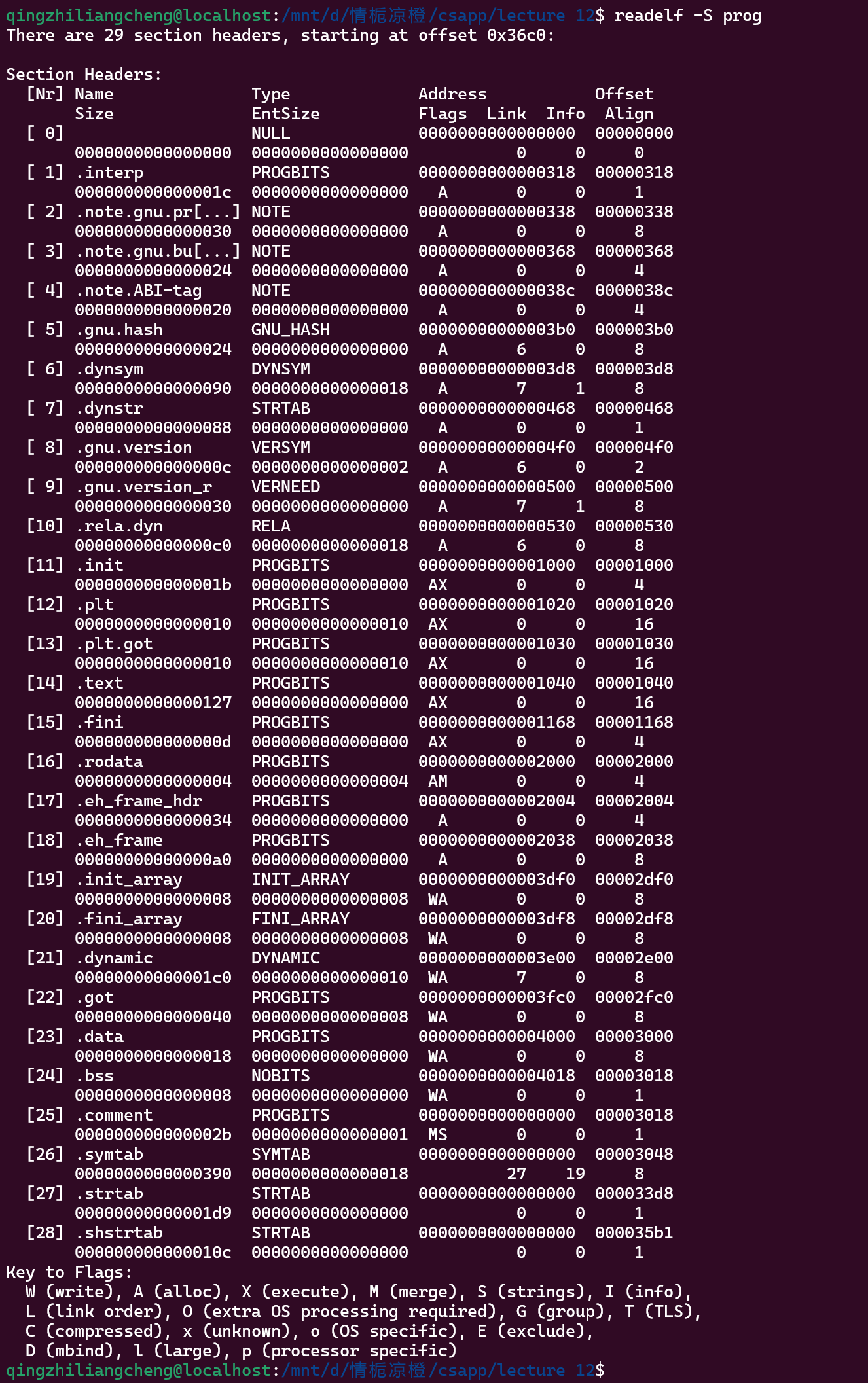
在这里面能看到很多section的名字
根据上面ELF中的 有这么几个
- .text section 代码本身
.rodata section
read only data
比如 Switch语句中的 jump table
- .data section: 包含了所有初始化全局变量的空间
- .bss: 定义了未初始化的全局变量 -- 实际上这些变量并没有真正占用字节
.symtab section: Symbol table
关于符号,就是前面提到的:函数,全局变量和 static 变量。
- .rel txt section & .rel data section: 包含重定位信息
- .rel txt section: Addresses of instructions that will need to be modified in the executable
- Addresses of pointer data that will need to be modified in the merged executable
- .debug: 将源代码的行号 和 机器代码中的行号相关联 方便调试
Linker Symbols
- Global symbols 全局符号
- 在module m中定义 但是可以被其他module引用
- 全局变量和函数定义 只要没有non-static 就是一个全局符号
- External symbols 外部符号
- global symbol的一种
- 被module m引用 但被其他module 引用
- Local symbols 局部符号
- 在m中定义 在m中引用
- functions and global variables defined with the static attribute.
- 这不是局部变量 局部变量是在堆栈上的编译器管理的 linker不知道局部变量
补一个知识 c语言中的static 关键字
在函数外部使用static
当static用于修饰一个全局变量或函数时,它的作用是限制该变量或函数的作用域到声明它的文件内。这意味着即使你在另一个文件中声明了一个相同名称的变量或函数,它们也不会发生冲突,因为它们彼此不可见。
// 文件 file1.c
static int globalVar = 50; // 仅在 file1.c 可访问
static void function() {
// 仅在 file1.c 可调用
}
在局部变量上使用static
当static用于修饰一个局部变量时,它的作用是改变该变量的生命周期,但不改变其作用域。具体来说,静态局部变量在整个程序运行期间都存在,而不是在每次进入其定义的代码块时创建、离开时销毁。这允许局部变量保留其值于多次函数调用之间。
#include <stdio.h>
void count() {
static int counter = 0; // 生命周期为整个程序执行周期
counter++;
printf("Counter: %d\n", counter);
}
int main() {
count(); // 输出 "Counter: 1"
count(); // 输出 "Counter: 2"
count(); // 输出 "Counter: 3"
}
Local non-static C variables vs. local static C variables
local non-static C variables: stored on the stack.
local static C variables: stored in either .bss, or .data(看赋值)

像如这个例子 就会在.data文件中 编译器会为这两个x都在.data文件中分配空间 需要定义一些名字来消除歧义 比如x.1 x.2
How Linker Resolves Duplicate Symbol Definitions
如果多个module中出现了多个一样的符号的定义 该怎么处理?
把symbols分成了strong 和 weak
- strong: 函数名称, 已初始化的全局变量
- weak: 未初始化
Linker's Symbol Rules
Rule 1: Multiple strong symbols are not allowed
这意味着如果在多个模块中声明一个相同名称的函数 -- linker error
Rule 2: Given a strong symbol and multiple weak symbols, choose the strong symbol
注意这里 如果原文为弱符号引用 会被解析为强符号的引用
Rule 3: If there are multiple weak symbols, pick an arbitrary one
任意选一个
如果用 gcc -fno-common 在多个弱符号的时候 编译器会报错
-> global variable -- avoid if you can
use static, initialize it
如果在引用外部变量 用extern属性告诉编译器 extern 关键字在C语言中用于声明一个变量或函数,表明它是在另一个文件中定义的。
static有点像Java的成员变量一样
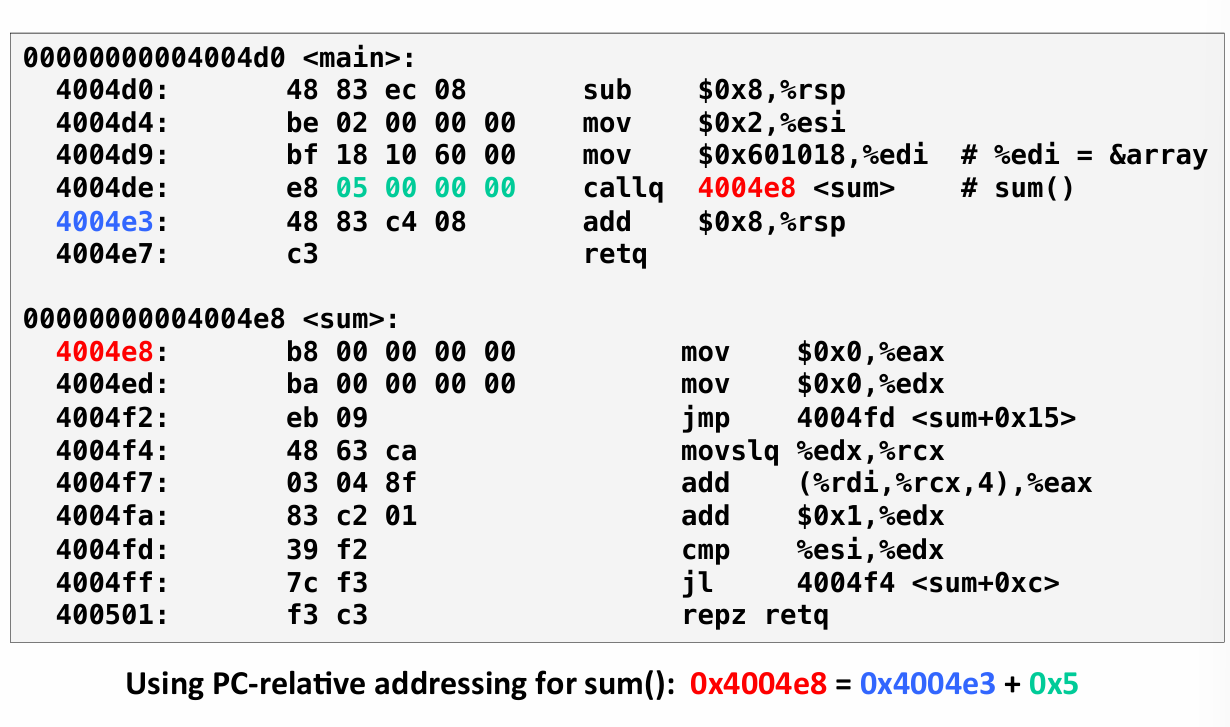
Detail Step 2: Relocation
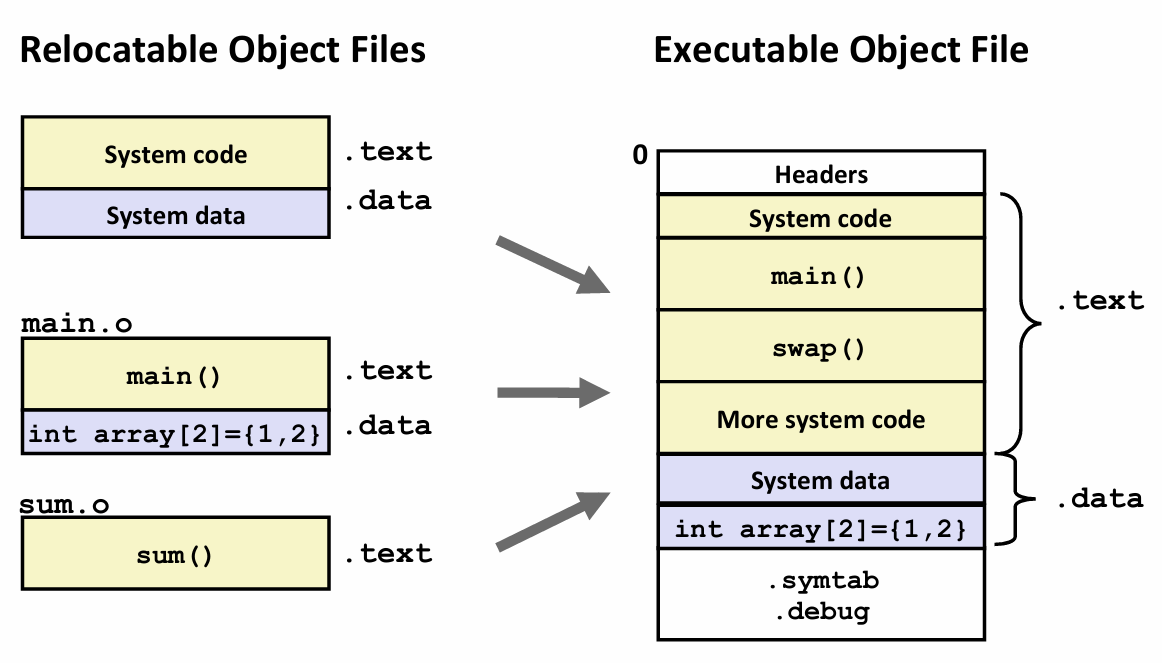
还是刚刚那个例子
main.o 有代码 在.text中 有初始化的变量 在.data中
sum.o 只有代码
还有一些system的code和data, 这是lib.c 在运行程序的时候 做的一些提前的准备工作 包括一些初始化
包括我们的代码运行前和运行后
运行前做的最后一件事情是 调用main函数
把所有的代码 放到 每个 model的文本部分中
再合并过程中 需要改变不同符号的地址
需要给main选一个地址 然后把main中的符号的引用 换成新的偏移
关键是在编译的时候 编译器并不知道未来linker会选择哪个地址
所以编译器会向成为重定位条目的链接器创建一些提醒
然后存储在了目标文件的重定位部分中
这里注意啊 只有.o 文件在objdump的时候能看见
我一开始用的prog不行 prog已经完成了重定向了 所以就看不见重定向标签了
gcc -c sum.c -o sum.o
gcc -c main.c -o main.o
objdump -d --reloc main.o
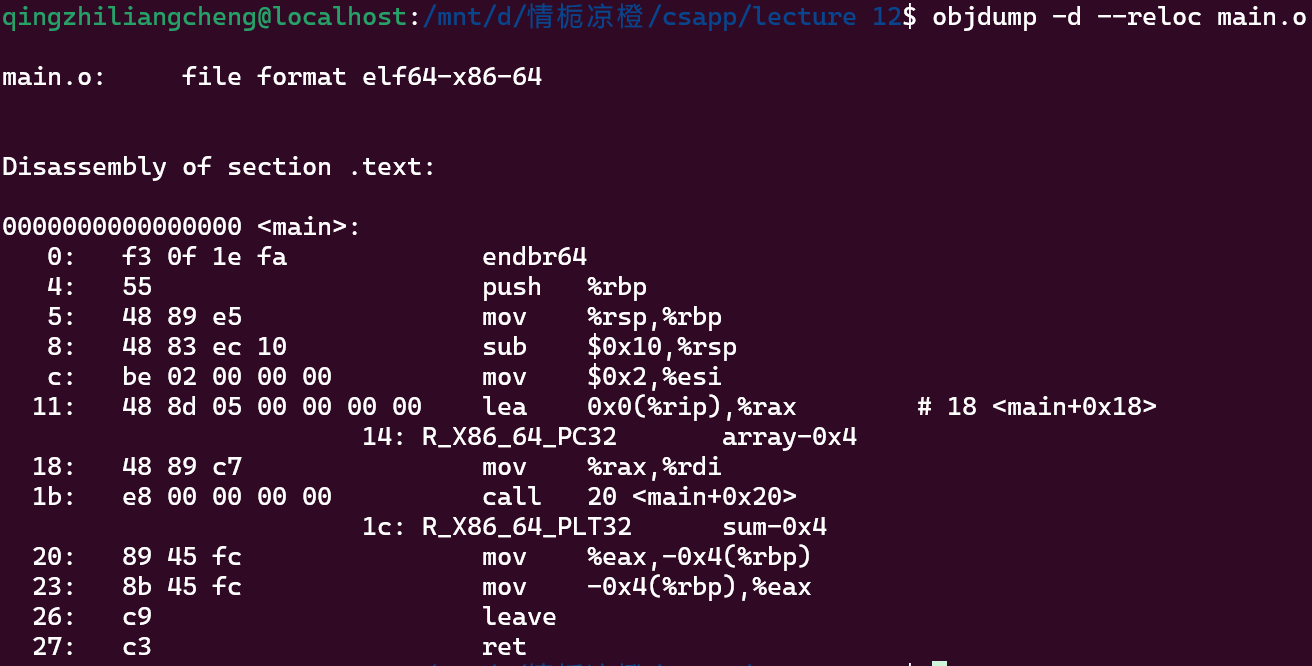
这些重定位条目是链接器的指令
这里有两个地方需要重定义 一个是array全局变量 一个是函数
在sum函数中 第一个参数是array 第一个参数是edi寄存器
但是这个时候编译器不知道array的地址 -- 所以只是传了一堆零
然后写了个标签提醒linker
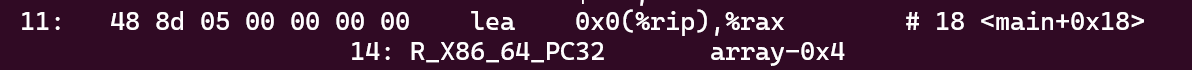
他在偏移量14出告知链接器 在你重定位main.o的时候 在.text部分中偏移量14的地方 改为这个32位地址形式的数组引用
48是11 8d是12
有一个细节 sum-4 array-4
确保偏移量的计算从下一条指令的地址开始
具体来说就是PC在运行到这条指令的时候 事实上PC放的是下一条指令的地址 一条指令4个字节
当一条指令需要跳转到某个符号的时候 array这个地址是相对于当前指令的偏移量
而PC中存的是下一个指令的地址
调用的时候是用PC的地址算的 所以多算了4个字节 需要减出来
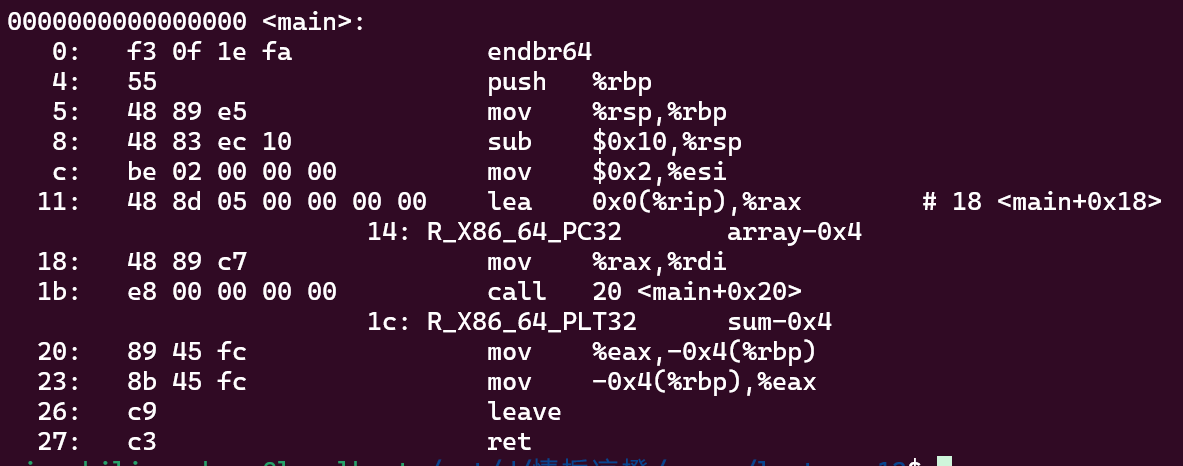
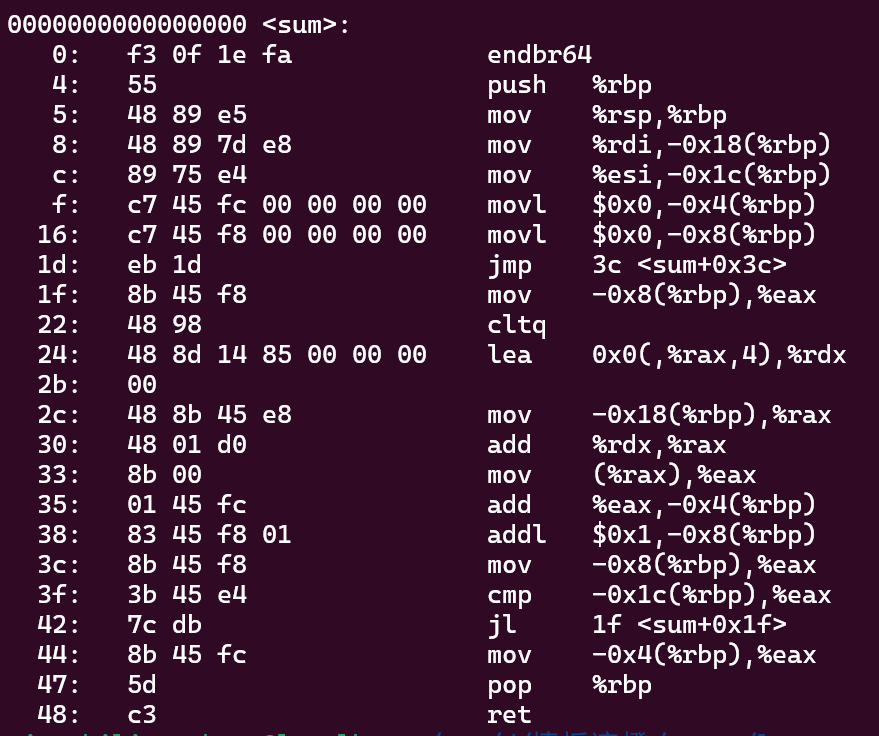
重定向完
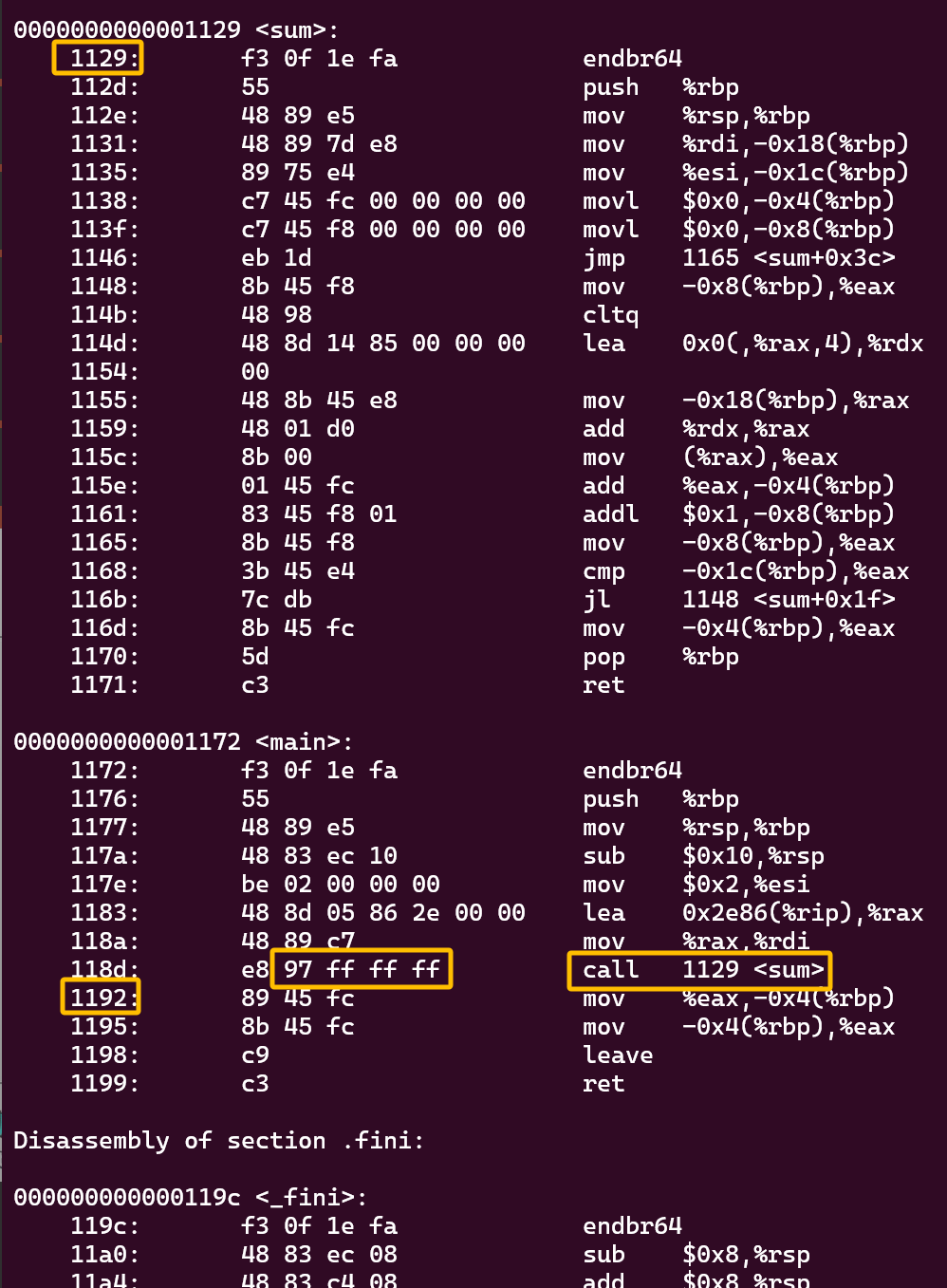
这里很有意思 ppt中的是main在上面 sum在下面(地址高)
按我的来看
我们关注的是画框的四个数
首先能看到调用sum的时候是call 1129 其实就是 sum开始的地址
那这个1129咋来的
就是用的当前PC 1192 + 97ff ff ff (是-105,问的AI)
刚好就是跳过去
换句话说这里填的97 ff ff ff咋算的 就是sum的地址和这条指令的偏移量 又-04
这里注意我的是main在下面 但是这个偏移量是个负数 -04 其实减的更大了 合理
Loading Executable Object Files
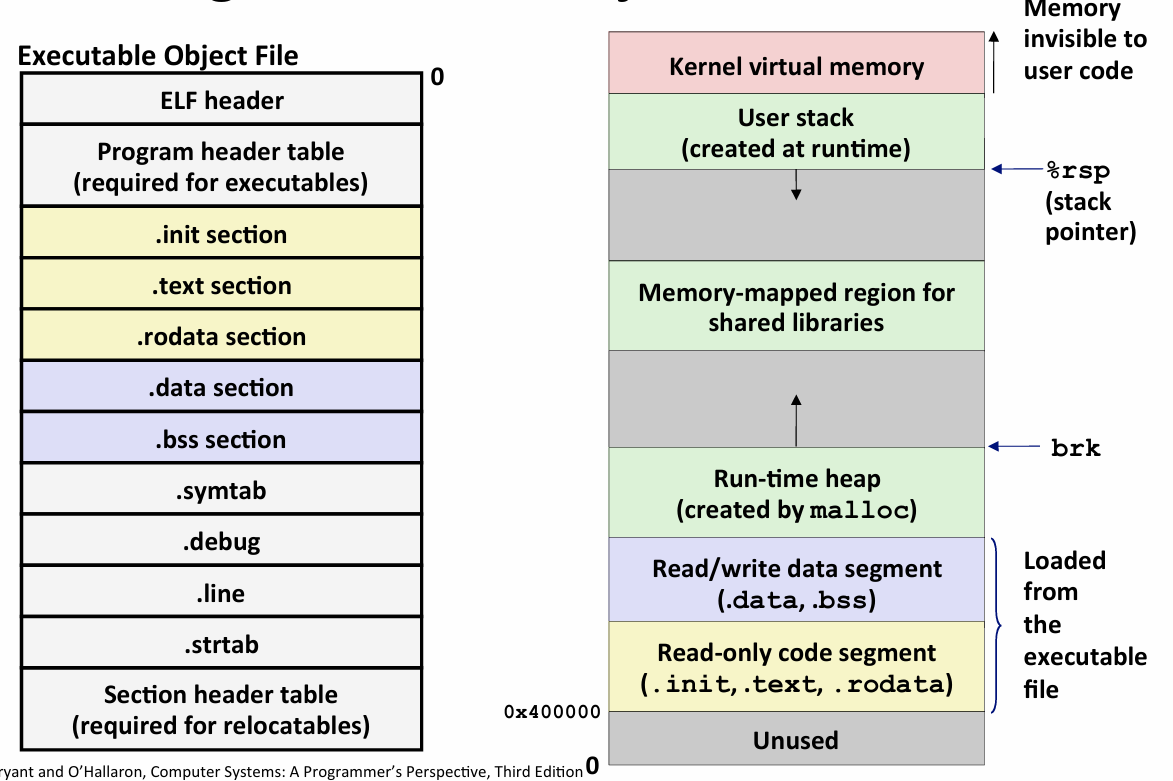
一旦linker 生成了 Executable Object File -- 该对象可以加载代码和数据
该对象直接加载到内存而无需进一步修改
右边这个 就是 每个Linux程序看到的内存地址空间 -- 其实就是虚拟内存
从0开始 而且每个文件都加在到了0x400000
我们在写代码的过程中 由于模块化的思想 可能会写好多.c文件
就会有好多.o文件
这样gcc编译的时候的指令就会很长
Old Solution: Static Libraries
静态库是一种包含多个.o 文件的 archive file(归档文件) .a扩展名
- 假设有foo.o 和 bar.o 两个文件 会合并到一个名为libfoo.a的静态库中 并且存在索引记录者两个文件的位置
- 如果你的程序中有未解析的符号(如
func()),链接器会检查指定的静态库(如libfoo.a)中的索引来查找这个符号,并尝试解析它 假设
libfoo.a中的foo.o文件包含了func()的定义,那么链接器会将foo.o链接到最终的可执行文件中,从而解决func()的引用。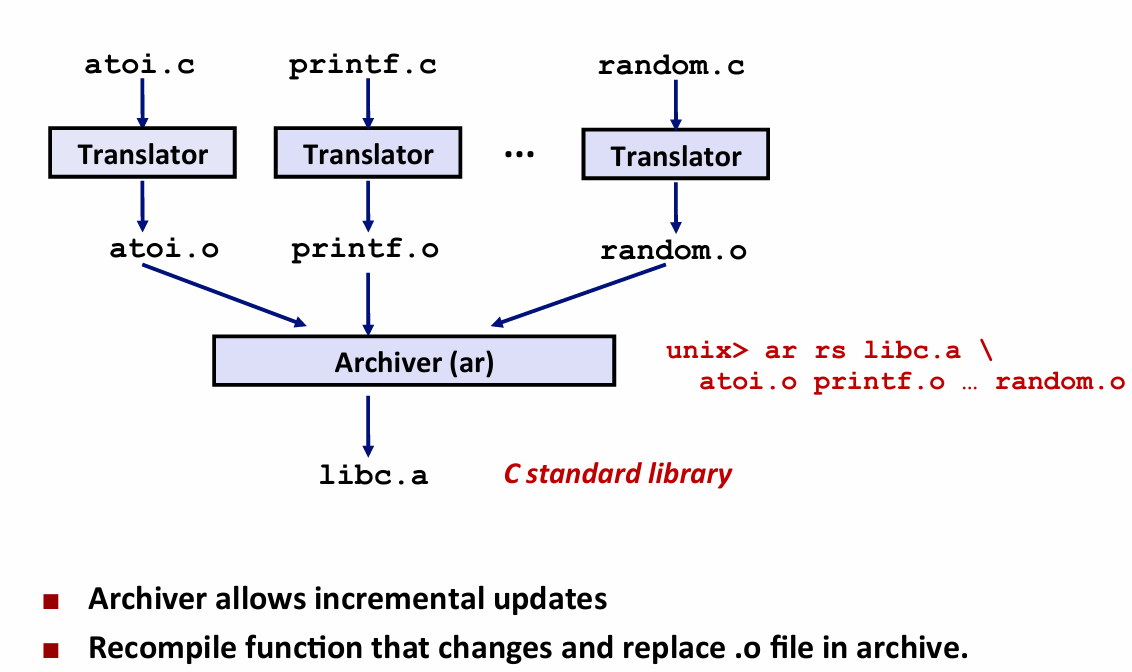
ex libc.a libm.a

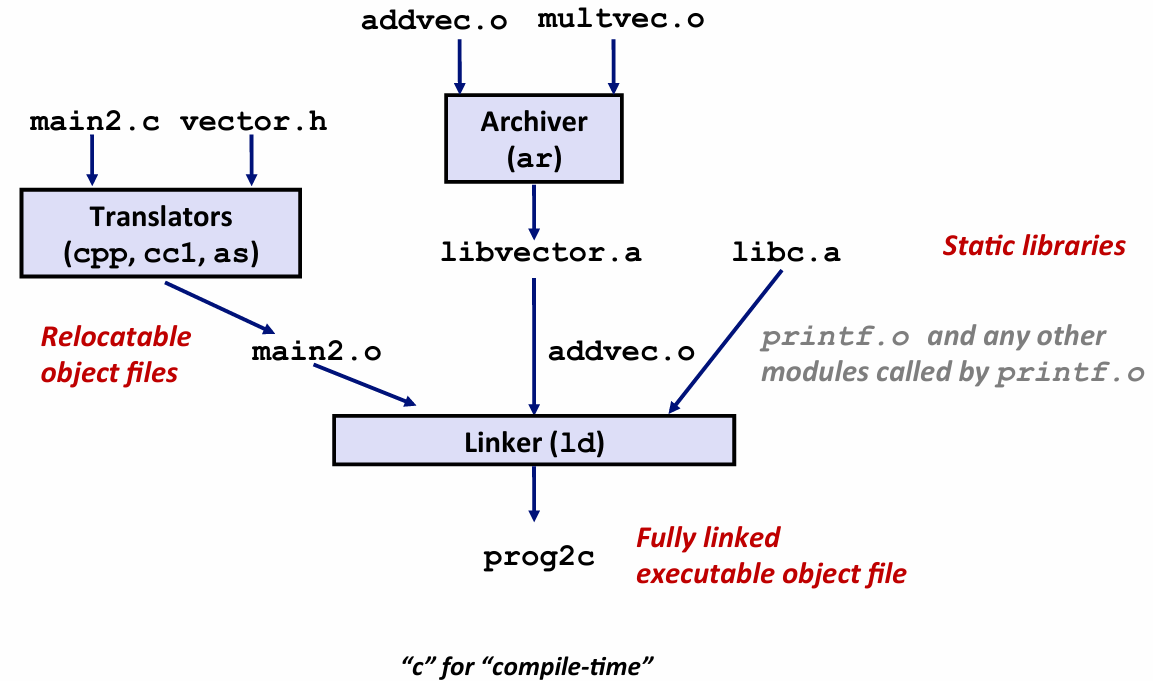
只是拉出来addvec.o 部分 并忽略其他部分
linker‘s algorithm for resolving external references
按照命令行中指定的顺序扫描 .o files and .a files
维护一个未解析的外部引用列表
遇到.o 和 .a文件的时候 链接器会尝试匹配未引用列表中的引用
如果扫描结束后还有未解析的引用 会报错
关键在于 顺序
如果使用错误的顺序 可能会出现一些奇怪的链接器错误

第二种情况会报错 建议放在最后
Modern Solution: Shared Libraries
Static Libraries have disadvantages:
存储重复
基本上每个函数都需要标准库 会导致可执行文件中包含相同的库代码 -- 会增大文件大小
运行重复
内存中运行的多个程序会加载相同的库代码多次
如果库更新,每个依赖该库的程序都需要重新编译
shared Libraries
包含代码和数据 动态加载和连接
meaning 在应用程序启动的时候 动态加载所需的共享库 而不是编译的时候连接进去
链接延迟了
windows .dll
Unix/Linux .so
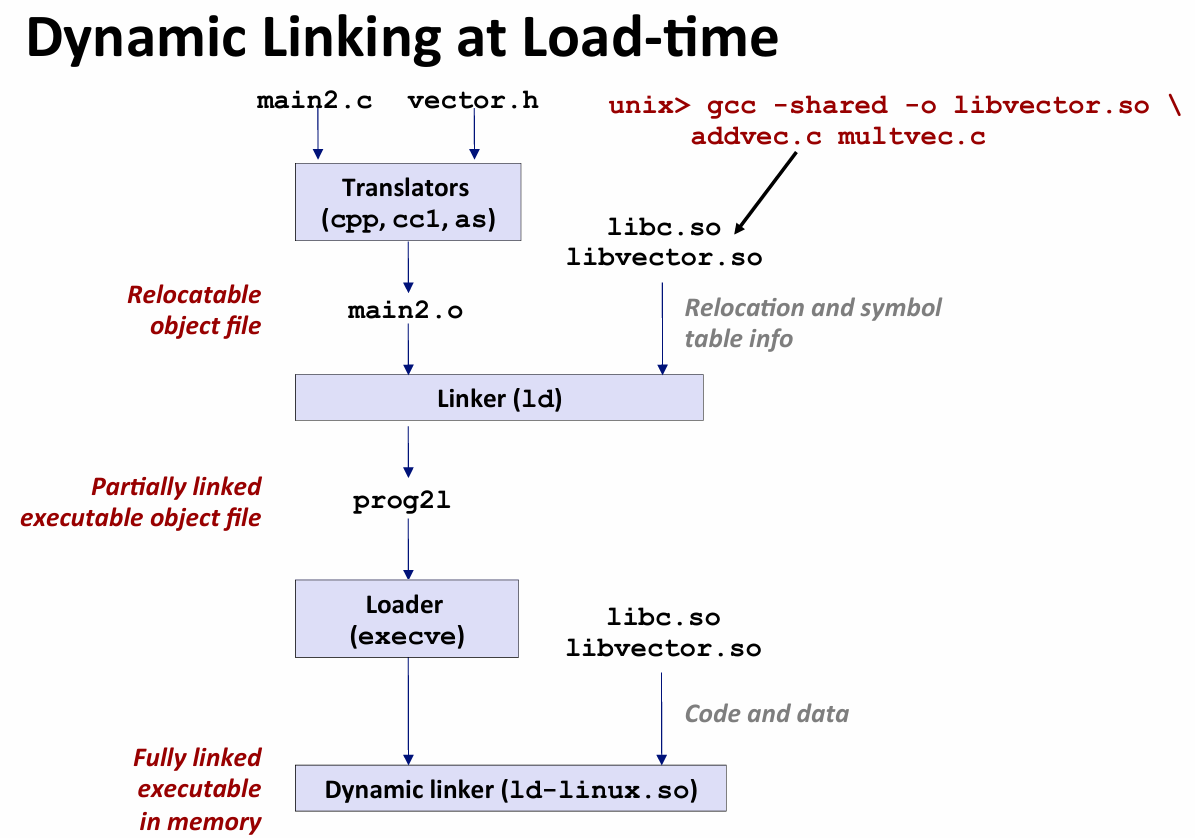
静态库的工作原理
静态库的本质:
- 静态库(
.a文件或.lib文件)是一组目标文件(.o或.obj)的集合。 - 在编译时,链接器会将你程序中用到的函数从静态库中提取出来,并直接嵌入到最终的可执行文件中。
- 理论上,静态库确实只会链接你程序中实际调用的函数。例如,如果你只调用了静态库中的
funcA和funcB,那么只有这两个函数会被嵌入到可执行文件中。 但即使如此,仍然存在以下问题:
静态库的问题
存储重复
- 静态库(
- 即使静态库只包含你用到的函数,这些函数仍然会被完整地嵌入到每个使用它们的可执行文件中。
比如,两个不同的应用程序都调用了
funcA,那么funcA的代码会被分别嵌入到两个可执行文件中,导致重复存储。运行时重复
- 运行时,每个可执行文件都会加载自己的静态库副本到内存中。
如果多个程序同时运行,即使它们都只调用了同一个函数(比如
funcA),这个函数的代码仍然会在内存中存在多份,浪费了宝贵的内存资源。维护困难
- 如果静态库中的某个函数有 bug 或需要更新,所有依赖该静态库的应用程序都需要重新编译和链接。
例如,假设你在静态库中修复了一个安全漏洞,那么所有使用该库的应用程序都需要重新编译并发布更新版本。这增加了维护成本。
动态库的优势
相比之下,动态库(
.so文件或.dll文件)解决了这些问题:
- 共享代码:
- 动态库在运行时被加载到内存中,多个程序可以共享同一个库的实例。
- 例如,
libc.so只需要加载一次,所有使用它的程序都可以共享它。
- 易于更新:
- 动态库可以在不重新编译应用程序的情况下进行更新。例如,修复了
libc.so中的一个 bug 后,只需要替换这个库文件,所有依赖它的程序都会自动受益。
- 动态库可以在不重新编译应用程序的情况下进行更新。例如,修复了
- 节省存储空间和内存:
- 因为动态库是共享的,所以不会像静态库那样造成存储和内存的重复
Case study: Library interpositioning
库打桩 库拦截
Linux 链接器支持一个很强大的技术,称为库打桩 (library interpositioning),它允许你截获对共享库函数的调用,取而代之执行自己的代码。使用打桩机制,你可以追踪对某个特殊库函数的调用次数,验证和追踪它的输入和输出值,或者甚至把它替换成一个完全不同的实现。
下面是它的基本思想:给定一个需要打桩的目标函数,创建一个包装函数,它的原型与目标函数完全一样。使用某种特殊的打桩机制,你就可以欺骗系统调用包装函数而不是目标函数了。包装函数通常会执行它自己的逻辑,然后调用目标函数,再将目标函数的返回值传递给调用者。
打桩可以发生在编译时、链接时或当程序被加载和执行的运行时。
下面在主程序main.c中跟踪对库函数malloc 和 free的使用情况
编译时打桩
本事是借助#define预处理 在预处理阶段替换malloc 为自己实现的mymalloc
mymalloc.c
#ifdef COMPILETIME
#include <stdio.h>
#include <malloc.h>
//定义malloc 包装函数
void *mymalloc(size_t size)
{
void *ptr = malloc(size);
printf("my_malloc:%d=%p\n", (int)size, ptr);
return ptr;
}
//定义free 包装函数
void *myfree(void *ptr)
{
free(ptr);
printf("my_free:%p\n", ptr);
}
#endif
malloc.h
#define malloc(size) mymalloc(size)
#define free(ptr) myfree(ptr)
void *mymalloc(size_t size);
void myfree(void *ptr);
main.c
#include <stdio.h>
#include <malloc.h>
int main() {
int *p = malloc(32);
free(p);
return 0;
}
# -D宏名
gcc -DCOMPILETIME -c mymalloc.c
# 因为有-I.参数,所以会打桩,它告诉C预处理器在搜索通常的系统目录之前,先在当前目录中查找malloc.h,main函数中的malloc会变成mymalloc
gcc -I. -o main main.c mymalloc.o
./main
my_malloc:32=0x563cfd6092a0
my_free:0x563cfd6092a0
通过预编译查看main.i
gcc -I. -E -o main.i main.c
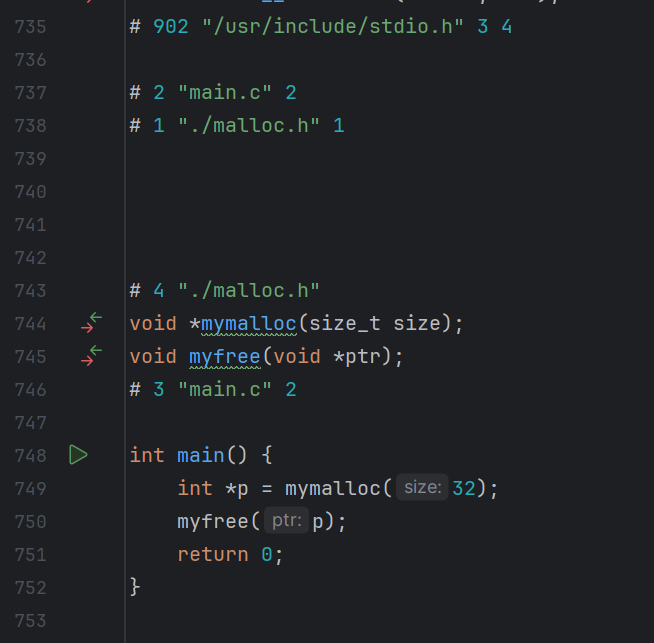
可以看到malloc变成了mymalloc,free变成了myfree
链接时打桩
Linux的静态连接器支持使用--wrap f标志进行链接时打桩。这个标志告诉链接器,请把符号f的引用解析为__wrap_f,并且将对符号__real_f的引用解析为f。
举个栗子:
--wrap malloc <==> 将符号malloc的引用解析为__wrap_malloc,将__real_f的引用解析为malloc。
运行时打桩主要依靠动态链接器的LD_PRELOAD环境变量。如果LD_PRELOAD环境变量被设置为一个动态库的路径名的列表(以空格或分隔间隔的列表, 一个元素也可以),那么当你加载和执行一个程序,需要解析未定义的引用时,动态链接器会优先搜索LD_PRELOAD库,然后才会去搜索其它的库。
https://blog.csdn.net/weixin_51696091/article/details/129086658