Lecture 19 Dynamic Memory Allocation:Basic Concepts
之前的Lecture讲到了虚拟内存,虚拟内存是一种巨大的抽象,a lots of bytes, 那么我们需要一定的机制来管理和使用它,这就是未来两个Lecture的主题: dynamic memory allocation, 分配的基本原理?如何使用它们来管理系统中的虚拟内存?
Basic Topics of Dynamic Memory Allocation
应用程序使用Dynamic Memory Allocator(动态存储器分配器)去操纵虚拟内存,去构造、分配以及释放程序所需要的虚拟内存,他们是一个动态变化的内存空间。这个空间在称为heap的区域被维护。
所有的语言都有一些用来分配和操纵动态变化的内存空间的方法,比如在C语言中使用的是malloc的方式,而在java, C++中有new方法
allocator将heap视为不同大小的内存块组成的集合,这些内存块要么是allocated(分配)的,要么是free(空闲)的,分配意味着已经有应用程序占用,而空闲意味着待分配给应用程序
allocator有两种:
- 一种是我们在C语言中用到的malloc的那种分配器,这种分配器应用程序将会决定是否显式分配内存并在用完之后决定是否显式释放内存,换句话说就是程序员在写程序的时候手动申请(malloc) 和释放内存(free),系统不会释放分配的任何内存,这种分配器叫Explicit Allocator(显示分配器)
- 但在很多别的语言中,都存在Implicit Allocator(隐式分配器), 程序员只需要申请内存,不需要手动释放,释放工作由系统自动完成,比如在Java中就存在Garbage Collection(垃圾回收机制),自动识别不在使用的内存并释放它
today discuss explicit memory allocaiton. next class will discuss implicit allocators.
C语言中的分配器由standard C library中一组叫做malloc包的函数提供

malloc函数用于分配内存,它把以字节为单位的参数作为函数的输入参数,返回一个指向内存块的指针,该内存块至少包含(注意是至少!)所声明的大小的字节,因为该块会在x86-64系统上以16字节对齐

free函数用于释放内存,它以一个先前调用malloc时返回的指针作为参数
other functions: calloc(another version of malloc), realloc, sbrk(增大缩小heap,可以用sbrk申请更多的虚拟内存放入heap中)
malloc example, 注意我们经常使用sizeof来获取大小,malloc返回的是一个void* 泛型指针,我们需要将其转换为int* keep the compiler happy(老师原话hhh), 其实我觉得这样未来才能做一些指针运算之类的,知道增量是多少或者说解引用的时候解引用多少空间.

接下来了解malloc和free的内部实现
但是这里做了一个假设,虽然我们知道虚拟地址或者说地址是按照字节编址,这里只聚焦于看字,以字为单位化块 这里假设一个格子四个字节
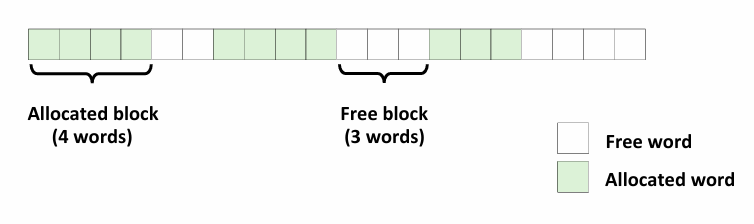
对于malloc和free
- 应用程序可以发出任意顺序的malloc和free请求,也就是说,程序员可能会以不可预测的方式申请和释放内存
- free请求只能释放之前由malloc分配过的block, 不能释放没有被分配或者错误地址的内存块
- 内存分配器无法控制分配请求的数量或大小,这些是由应用程序决定的
- 内存分配器立即响应malloc请求,意味着不能重排序或者缓冲分配请求以获得更好的结果
- 不能覆盖使用过的内存
- 分配出来的内存必须满足对其要求
- 32位系统(x86): 8字节对齐
- 64位系统(x86-64): 16字节对齐
- 不能进行内存压缩
分配器是一种时间和空间上的权衡,尝试尽可能的块,但我们希望高效的利用内存
我们定义了速度和内存效率指标: throughput(吞吐量), memory utilizaiton(内存利用率)
吞吐量实际上是每单位时间内完成请求的数量
内存利用率是max Aggregate payload(最大有效载荷)和Current heap size(当前堆大小)的比值,payload是指的我们调用malloc(p), 事实上我们申请了p字节的有效载荷,也就是说,在第 Rₖ 次请求执行完之后,Pₖ 是当前所有还没被 free() 的 malloc 块的 payload 总和。在这里其实是假设了heap size只增不减,但是事实上在真正的malloc包中不是这样的
我们的目标是maximize throughput and peek memory utilizaiton(最大吞吐量,峰值内存利用率)
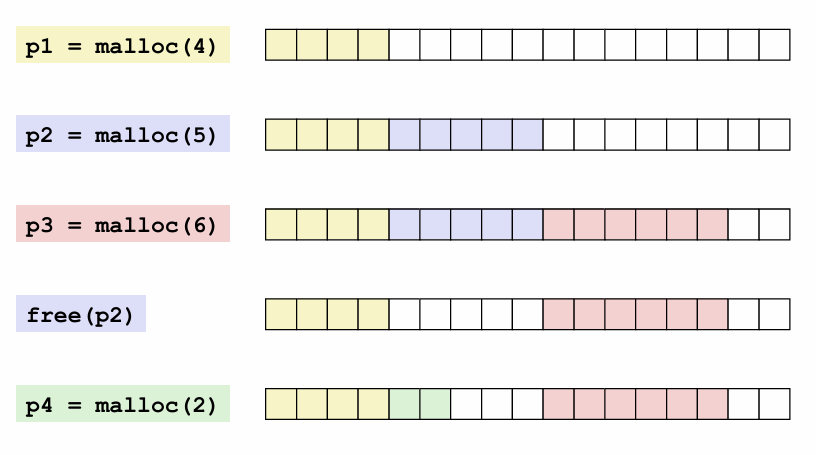
上面的例子事实上是一个fragmentation(碎片)的例子,fragmentation有两种,这个在操作系统上加过
- internal fragmentation
- external fragmentation
对于有效负载小于块大小,其实这里注意啊,上面也提到了,我们malloc(p), 是申请了p字节的有效载荷,但是我们分配出来的并不一定是p个字节啊,需要对齐,所以说没用到的就是internal fragmentation,不过其实注意一下 block size中除了payload和padding之外,metadata(元数据)也占用空间,而这也是内部碎片的一部分
换句话说,内部碎片的大小: block size - payload
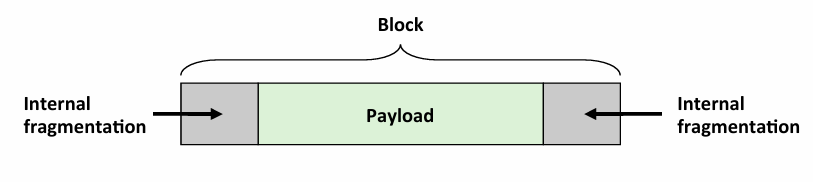
而下面这个例子,就是external fragmentation的一个例子

How do we know how much memory to free given just a pointer?
一种方法是,在每个块的开头使用一个字大小的区域来记录大小,不过注意啊这个块的开头,是指的payload前,换句话说就是我所占用的块前面有一个header,用来存,metadata,metadata其中包括block size, 后面才是payload,然后可能还会有对齐多分配的一些碎片
注意另一个点 malloc返回的是payload的起始位置
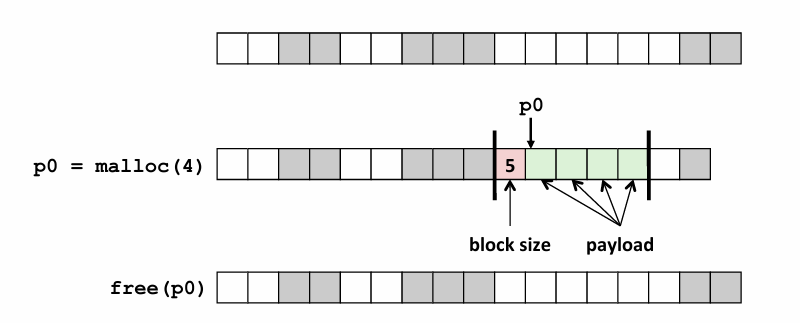
How do we keep track of the free blocks?
Methods 1: Implicit List using Length(隐式空闲链表): 所有内存块都用一个链表串起来,每个块都有长度,无论是allocated的还是free的,然后遍历块的时候,根据大小跳过去判断,不过这要扫描整个堆

Methods 2: Explicit List among Free Blocks using Pointers(显式空闲链表) -- 只串联空闲块,每个空闲块可能会保存两个指针prev, next 不过图中是保留了一个指针

Methods 3: Segregated Free List(分离空闲链表) -- 把空闲块按大小分类,没类用一个链表,每次分配时区对应的大小或者大小区域的链表中去找 -- 怎么把握粒度?
Methods 4: Blocks Sorted by Size -- 通过数据结构比如红黑树等,对free block进行排序
其实,看到这里我突然想起来操作系统中的动态分配,各种算法,首次适应算法,临近适应算法等等,甚至有的有个表来存每一个block的大小等等 其实当时我学LCU操作系统的课的时候,没和heap和malloc联系起来,也没考虑到前面有metadata也算内部碎片的一部分(其实后面考试是速成的,没认真看书,但我不知道书上有没有),另外CSAPP算是导论性质的,这一部分就是操作系统的范畴,如果要细究的话,还是得去看操作系统的书
(eee 看完之后过来补得一句话,后面讲了首次适配这些算法了哈哈哈哈哈)
Implicit Free Lists
这里只讨论了Methods1的实现方法
按照上面图的方法,在一个block中,我们要存取这个块的大小以及状态,而如果在元数据中用一个字来存储size,一个字来存储status,这需要两个字,是非常浪费的
为什么是两个字?
假设我们的size是size_t类型,allocated是bool类型,size_t占8个字节,bool占一个字节,但因为自动对齐,bool会自动插入7个字节的padding 然后后面才是我们的有效载荷。
一个好的方法是利用size末尾后面的0来存储status: 因为系统要求对8或者16字节对齐,所以size的二进制写出来最后三位或者最后四位一定是0,所以我们可以利用这几个0来存储状态
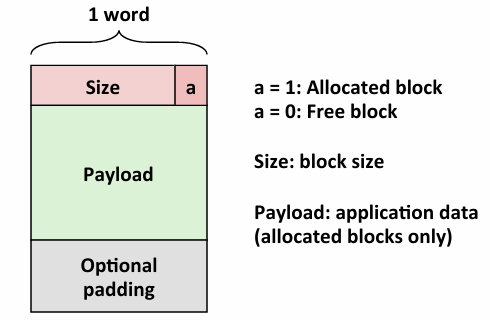
Detailed Implicit Free List Example: 我们假设word是4字节,8字节对齐
这里的设计是 所有块的有效负载都是从8字节边界开始的(为啥? 因为有效负载才是真实的数据,进CPU的时候最好对齐进去,这样取得次数少),所以需要再堆的开头设置一个unsed的字,然后达到了用8字节的最后一个或者说下一个8字节的前面这个块用来当header的效果,那么最后其实也是多着一个,有点像EOF,可以看做终止,但也有简化合并的效果
Finding a Free Block的过程
Methods 1: First Fit(首次适应)

绝了这个位运算,所谓首次适应算法就是每次都从头开始,不过这里的这个start其实不是unused,是第一个header的那个位置.
*p & 1 是拿最后一位,这里其实是看是否被占用;而下面的*p & -2是拿出了最后一位的其他位,其实CSAPP之前讲过,&一般用于掩码运算,所谓掩码就是利用 &运算 的特性 1关注这一位,0不关注这一位,而这里的1和-2其实都是有符号数,这里其实CSAPP也讲过,1就是0...01,而-1是1...11,那么-2就是1...10
Methods 2: Next Fit(临近适应算法): 核心思想就是顺着往下找,从最后一次在的位置继续往后扫描,事实上研究表面这会造成更多碎片
Methods 3: Best Fit(最佳适配算法): 找最接近的,这就需要排序了
Allocating in Free Block

这段代码的核心在于newsize的操作 进行了取偶,以及newsize|1这是把最低位设为1表示这个已经被分配
Freeding a Block
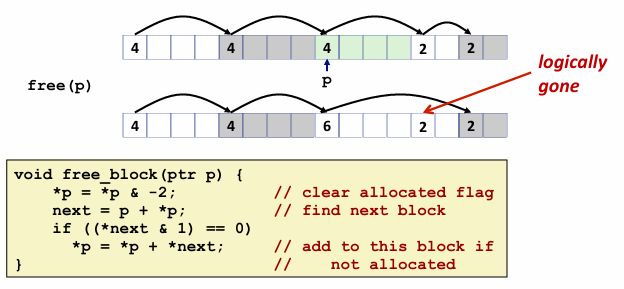
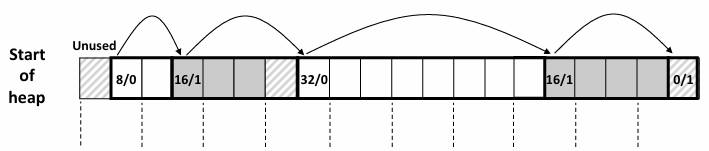
但这其实只是和后边合并了 和前面合并呢? 需要从前遍历了
这就需要一个像双向链表一样的结构了
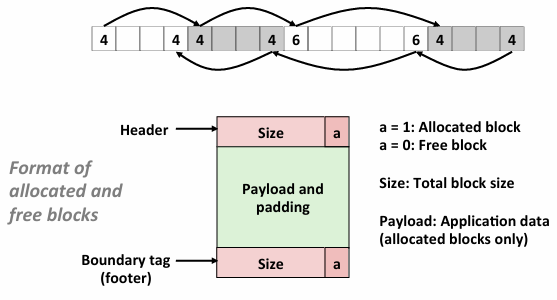
这样其实一共有四种情况:不需要合并,只需要和后面合并,只需要和前面合并,前后都需要合并
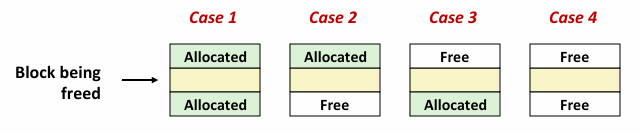
当然这造成了内部碎片,有没有什么方法不需要边界标志?
所以其实可以用字节对齐中的碎片
allocated不需要知道大小 free的需要知道大小
Garbage Collection
有一种称为Implicit Memory Management(隐式内存管理器)的内存管理器,为我们完成释放内存工作,这种想法就是Garbage Collection(垃圾回收)
有什么垃圾?

这个申请的128的地址存储在指针类型的变量p中,而变量是在栈区的,一旦return,这个指针就会永远丢失,那p指向的内存块就是garbage
那么Garbage Collection就会自动识别谁是垃圾并自动调用free -- 调用的是相同的free
那memory manager是如何知道内存合适可以被free?
如果我们知道将来不会请求访问该块 -- 就可以释放 但是很难预测
一种想法是扫描内存中的所有被分配的内存块,如果没有pointer指向 就认为是garbage
那么内存就需要能够区分指针和非指针,但是做不到,我们遇到一个64位的数,我们不知道这是一个块的起始地址还是一个大数
同时所有指针需要指向块头,因为我们free的时候要free到整个空间, 但事实上是会有一些指针指向内部
这些是一些挑战,最早研究garbage Collection可以追溯到1960年,直到今天也有人研究多线程的垃圾回收…… 不过今天只看最简单的
我们如何建立一个Garbage Collection?
首先我们把内存视为有向图,每个节点对应一个分配的块,每个边都是一个包含在该块某处的指针
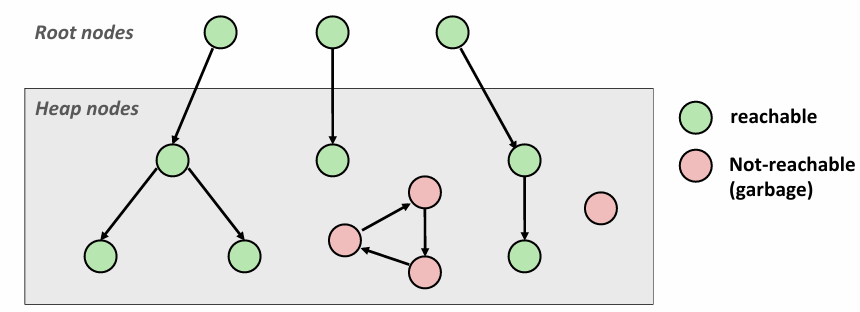
然后有一些称为根节点的特殊节点,它包含指向堆的指针,但不是堆的一部分,比如这是存储在栈上的指针,或者在寄存器中的指针变量,他们指向堆中的内存位置
如果对于heap中的已分配的块来说,如果存在一个来自root node的路径,那就不是垃圾
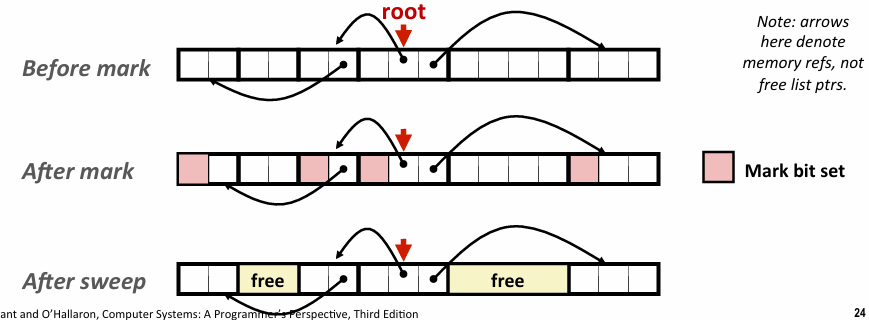
我们可以在每个内存块的头部额外加一个标记位,然后从根开始,通过遍历算法遍历能到达的每个节点并标记;然后清楚节点只需要遍历堆上的所有内存块,如果那个标记还是0,就说明是垃圾,可以free
事实上C语言没法区分是不是指针,但如果知道是指针的话,怎么找到beginning of the block?
Solution: 通过一个平衡二叉树来追踪所有已分配的内存块,没次分配一个新的内存块,就把他作为起始地址插入树中,查找的时候可以通过任意地址定位到它属于哪个块
Allocated Blocks:
[0x1000 ~ 0x1100)
[0x2000 ~ 0x2100)
[0x3000 ~ 0x3100)
Balanced Tree:
0x2000
/ \
0x1000 0x3000
If you get a pointer 0x2060, you search for <= key:
→ find 0x2000 → found the block!
因为这里 这个指针一定是被分配的空间 所以在树中最近的那个就是他的开头
每个块的头部都可以额外的用两个字来保存树的指针信息 -- 为了使树节点之间相互连接 -- 每个块都要保存left和right 如果是AVL或者红黑树的话,还可能会parent -- 这就是内嵌式树结构

Memory-Related Perils and Pitfalls
内存错误 is the worst the worst.
在C语言中,这一切都可能跟指针有关,所以需要好好理解指针
理解指针操作的第一步是要了解C语言中的运算优先级


好好理解
- 第一个是int类型的指针
int*变量名叫p(其实不同的编译器是不一样的,CLion会把这个指针符号跟着后面,而VS会跟着前面的int,我是趋向于第一种),而指针是一个地址,所以p打印出来就是地址,*p是解引用 - 第二个的核心在于数组运算符的优先级高于指针运算符,所以首先这是一个数组,数组名叫p,里面元素的类型是
int*类型,所以这是一个int*类型的数组,里面的元素指向一个int类型的空间,而里面可以放一个数组,通过指针来访问数组,这就是一个逻辑上变长的二维数组了 int **pp是指向int的指针的指针; 事实上可以看作是一个指针指向了一个数组,这与chat*指向字符串的机制是一样的int (*p)[13]这是一个指向大小为13的int型数组的指针int *f()函数int (*f)()一个函数指针,函数返回的是int- 后面的就算了呃呃呃
下面是一些经典的错误
经典的scanf错误 The classic scanf bug

如果不传取值符号,scanf就不知道把数据放到哪里
Assuming that heap data is ini alized to zero 经典的读取未初始化内存
分配错误大小的对象
覆盖内存
缓冲区溢出
误解指针运算
....