Lecture 08 Tree Indexes
today's agenda
- B+ Tree Overview
- Design Choices
Optimizations
B+树是在构建关系型数据库中建立索引的默认选择
在大多数dbms中调用CREATE INDEX -- 99的情况下 得到类似b+树的结构
首先概述b+树高层次结构 -- 与b树相比 +特性的含义
基本设计选择
实际优化的不同方法 -- 当今实际系统所采用的实例
B+Tree Overview
the B plus tree is a sort of category of data structure called B trees.
在数据库文献或者系统中 有一类存在称为b树的数据结构 --- 其实是b+树
比如在Postgres中他们称为b-树 但实际上是结合了B link等现代技术的 的 b+树
-> 所以我们必须着眼于 所有的b树
关于b+树 并无原始论文记载, 大家普遍引用的是1979年IBM研究人员提出的《无处不在的b树》的概念

Ubiquitous B-Tree | ACM Computing Surveys
B+树的原始作者 Bayer和McCreight并没有明确界定B+树中的B代表什么含义 通常情况下 人们称为 balanced, broad, bushy 也可能用的自己名字的首字母
B-Link tree CMU的论文 Efficient locking for concurrent operations on B-trees | ACM Transactions on Database Systems
如果查阅Postgres源码中讨论b树的目录 -- 那么使用的是b树而非b+树
bw树是微软推出的一种技术 -- b+树的无锁形式
A B+Tree is a self-balancing, ordered tree data structure that allows searches, sequential access, insertions, and deletions in O(log n).
与一般binary search tree区别在于 -- have more than two children
因为我们系统最小random IO
B+树 可以再进行查找时 将随机IO转换为顺序访问
A B+Tree is an M-way search tree with the following properties:
→It is perfectly balanced (i.e., every leaf node is at the same depth in the tree)
→Every node other than the root is at least half-full M/2-1 ≤ keys ≤ M-1
→Every inner node with k keys has k+1 non-null childre
Postgres 稍微违反第一条
example
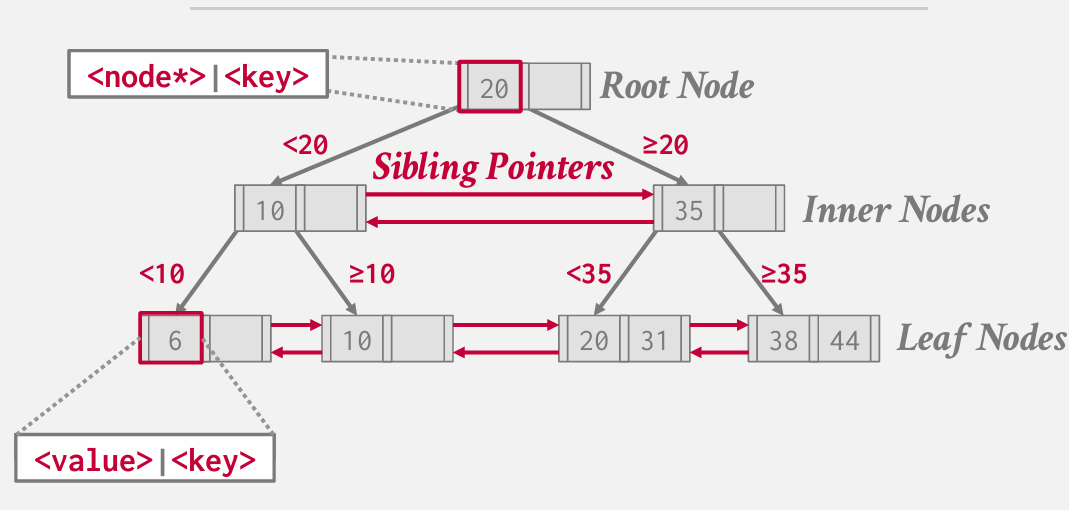
- root node, inner nodes, leaf nodes
- 节点内部:指向另一个节点的指针 + 键值
- 叶子节点:给定键 存储值 这个值可能是一个潜在的record ID 指向实际的tuple 或者是个page offset,在MySQL 或者 SQLite中 可能就是tuple本身
- 数字本质上 相当于路标
B-link tree: 每个节点每一层 都拥有兄弟指针 教科书上只有叶子节点有 但Postgres将其放置在了中层节点 内部节点
在节点内部放置的意义: split, merge
假设我想窃取某物 删除了10个 无需重组整个结构 可以简单的跟随指针 移动到别处
- 多线程 扫描过程中 获取锁 较高成本
只存在兄弟指针和向下指针 没有指针向上回溯
原因在于 当我们在这些节点上使用latch的时候 不希望有一个线程从顶部向下执行 而另一个线程从底部向上执行 这会导致死锁
其实兄弟指针也存在这种问题 所以需要处理
nodes
an array of key-value pairs
key from attribute that the index is based on
inner node:指向下方某页的指针
leaf node:the pointer of tuple
节点内的数组通常保持有序 但并非必须
how do you deal with null keys?
假设尝试使用b+树构建的索引并非唯一索引 -- 那么可能存在空值
通常情况下 要么全部置于末尾 要么全部置于开头
但根据查询需求 往往不希望首先看到空值 所以可能放在最后多一点
b+tree leaf nodes
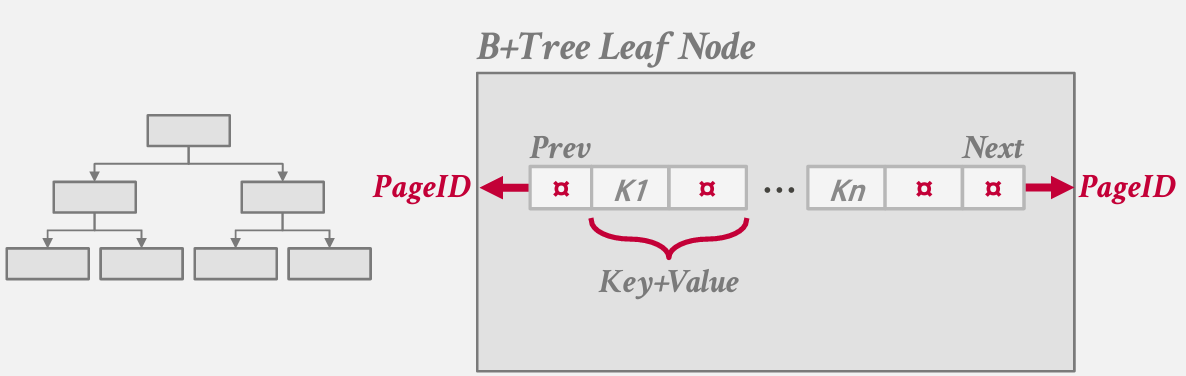
- prev 和 next 是前后page的ID
- key-value可以按照顺序逐一排序
inner node, the values just pointers and record IDs
也可以逐一排序 最常见的做法 在第一个数组中对key排序 然后另一个独立数组中存储value
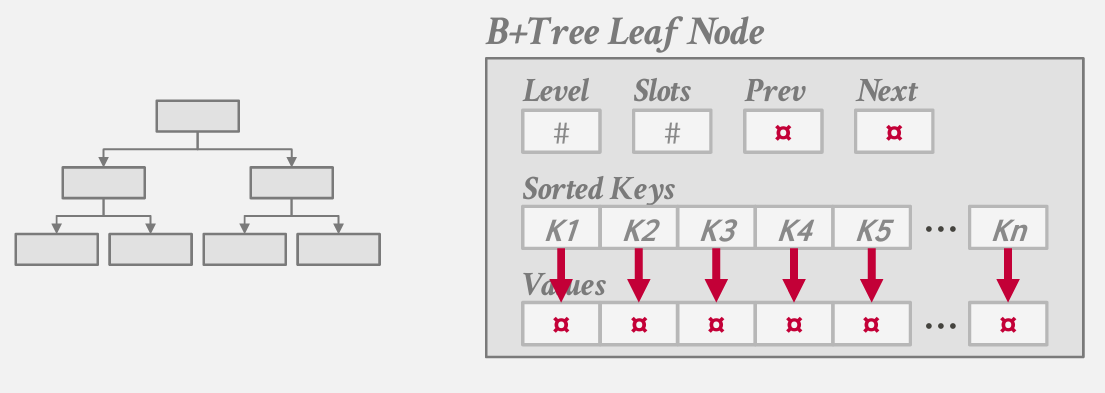
通过简单的算数运算offset 决定跳转
此外 还要额外的记录 比如 剩余槽位的数量slots, 正在查看的是哪个层级 level
leaf node values
Approach1: Record IDs
叶节点值本身可以是Record ID,指向某个位置 page number, offset
Approach2: Tuple Data
元组数据 --index organized storageLecture 04 Database Storage Part 2中的情况
SQLite, MySQL 默认
SQL Server和Oracle -- 创建表可以要求以索引组织方式存储
B-Tree vs. B+Tree
1972年提出的原始b树算法 所有的key-value都分布在整个树结构 --确实更加节省空间 因为它允许树高度更低
删除key35 它将从叶子节点移除,但由于B树的特性,这个键可能仍存在于索引或内部节点中,作为分隔不同子树的界限。这可能导致同一键在树的不同位置出现多次,从而浪费空间。
这里需要确认B-Tree的删除逻辑,当删除一个键时,如果该键同时存在于内部节点和叶子节点,是否需要调整内部节点?可能的情况是,删除叶子节点的键后,如果导致节点键数量不足,需要进行合并或重新分配,但内部节点的键可能不会被立即更新,除非影响到了结构。这可能造成内部节点中的键不再存在于叶子节点,但作为索引仍然存在,从而浪费空间。
在b树中 一个键值在树中仅出现一次 但该方法的问题在于 record id 指向的实际元组值可以在树中的任何位置 因此 现在如果我想要按顺序扫描以获取按某种顺序排序的所有所需键 可能需要上下遍历 因为我基本上必须执行广度优先搜索 而且在上下遍历树结构时 基本上需要锁住整个树
在b+树中 由于只有叶节点才是实际存放值的位置 一旦到达叶节点 就不必再维护树的上层部分中的任何latches
因为B+树的叶节点通常通过指针相互连接,形成一个双向链表。这种结构允许你从一个叶节点线性地访问相邻的叶节点,而无需返回到上层节点进行查找。
所以一旦到达叶子节点 就只需要沿着叶子节点搜 --- 其他线程可以在顶部及以上 自由执行他们想做的事
so b+树相较于b树的优势在于 我们将获得更佳的并发访问性能 我们将最大化或提升顺序IO的量
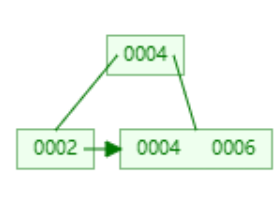
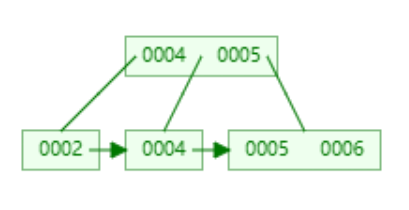
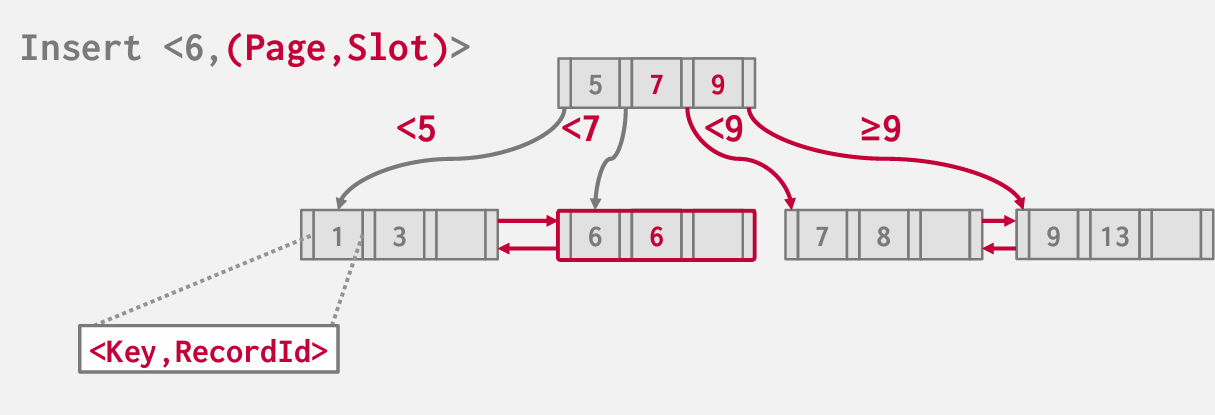
basic Operation -- insert
我们将遵循指引标记 向下遍历 直到找到某个叶节点
find correct leaf node L
Insert data entry into L in sorted order.
如果空间足够 那就按照顺序插入到叶子节点中
if there's not enough space, meaning the number of keys is full in the node, 我们将尝试将正在插入的叶节点一分为二 拆分成两个节点 将其平均分割 一半的key位于一侧 另一半的key位于另一侧 然后将列表中健的中间键 复制到 父节点
这一过程是递归的 如果父节点也满了 那么父节点也需要split
过程可视化界面:
basic Operation -- delete
是插入过程的逆过程 从根节点开始一路向下直至找到待删除条目的叶节点
如果没有 当然什么也不做
如果存在 就删掉
如果删除完 叶节点至少有一半是满的 就完成了
如果删除完 如果叶节点的key number 降至 m/2 -1
- 首先尝试重新分配(re-distribute): 跟随兄弟指针 找到同级的另一个节点 窃取一个key 只要不 不平衡 就行 可能需要父节点的微调
- 如果无法重新分配 需要L与某个兄弟合并 并相应更新父节点
递归的
过程可视化演示
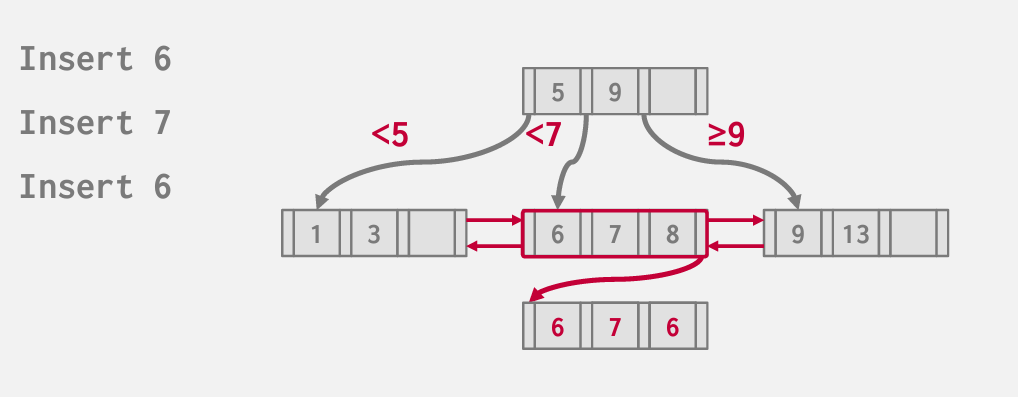
删除6
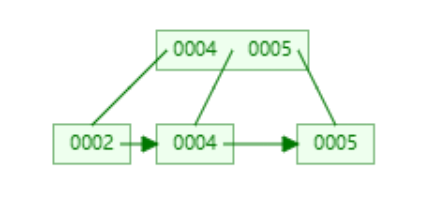
如果最大的degree=4 然后插入1 2 4 5 6 8 9
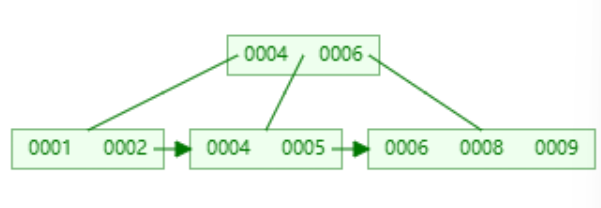
尝试删除中间的五个节点
so 对于b+树 能够执行一系列其他操作 这是无法通过哈希表完成的
在哈希表中 无法执行小于 大于的操作 无法进行任何部分键的查找 因为我们总是要对完整的键哈希
但是在b+树中 我们可以采取一系列技巧 即使包含键的部分信息或特定数量的属性 也能进行查询
还可以进行所谓的前缀查询 --这样的操作蛮难的 Postgres不执行该操作 Oracle, SQL Server 能实现这一功能 在Oracle叫做 skip scans
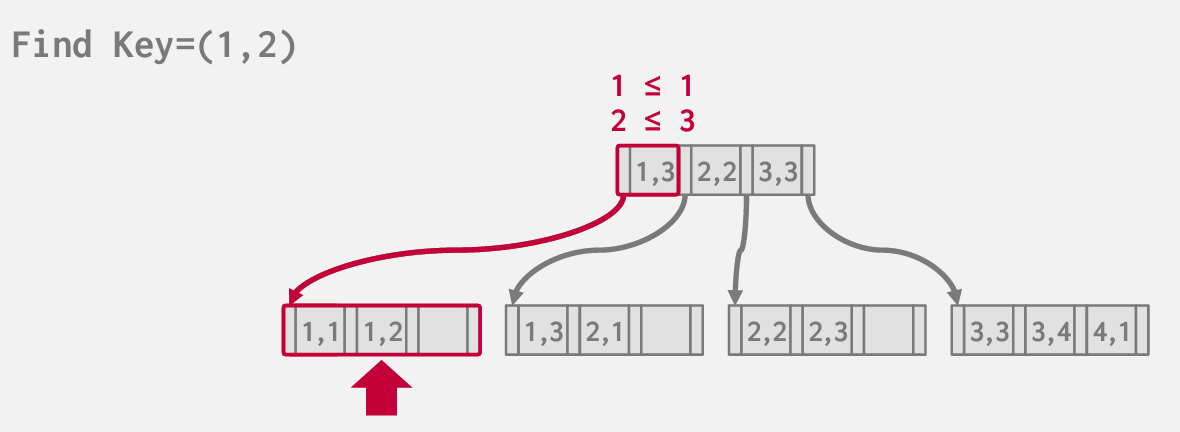
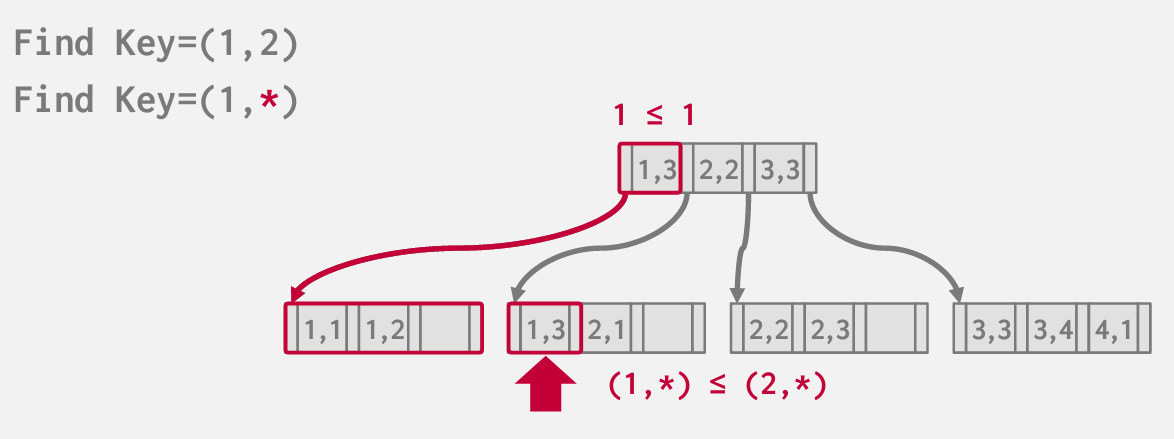
根据key找到第一个 然后根据兄弟指针 找到2位置
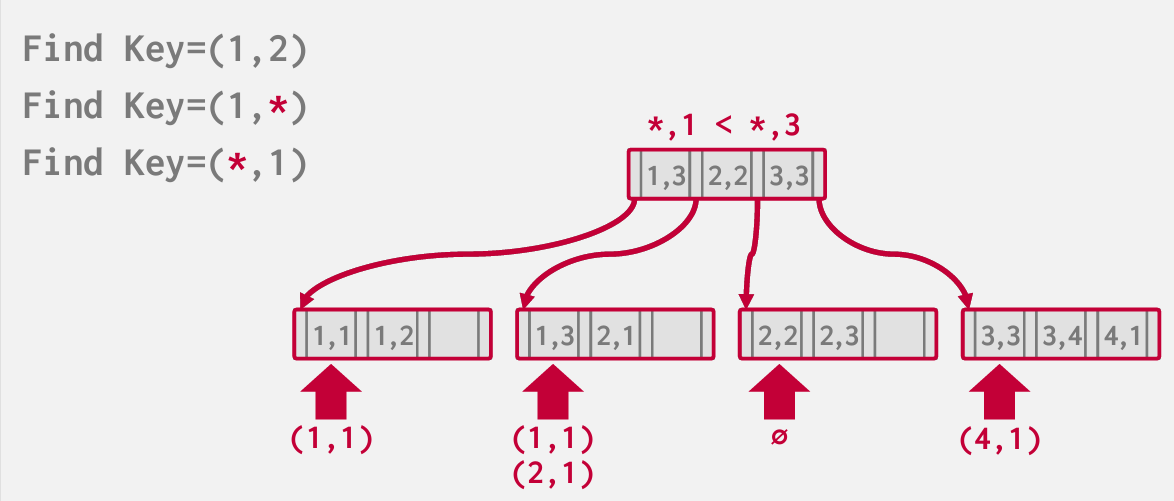
不得不查看所有内容
但在Oracle中 允许多个线程并行的遍历树的不同部分 然后最终将结果合并在一起
how do we handle duplicate keys?
如何反复插入key, duplicate key 而不违背logN
Approach1: Append Record ID
最常见的方法是维护一个隐藏列或隐藏属性 其中包含指向元组的记录ID 这保证了每一个键都是独一无二的
正因为可以进行前缀搜索 所以这一方案仍然有效
除了key 还有record ID 即 page number and offset
Approach2: Overflow Leaf Nodes
处理溢出的叶节点
如果叶节点已满 但我知道我正在插入相同的键 那么我只需可能地继续构建一个链表
但违背了logN
本质上和chain hash是相同的思路只不过开头是个树状结构
cluster indexes
聚簇索引
某些数据库允许在表上定义所谓的聚集索引 -- 即使关系模型本身是无需的 也可以实际指定存储在磁盘上的tuple按照某个索引的排序方式进行物理排序
在这种情况下 如果我拥有一个真正的聚集索引,那么无论在何处插入记录 实际的堆文件本身都将确保按照那种顺序排序
以SQLite为例,叶节点实际上存储了tuple 自动就形成了聚簇索引
但在某些数据库系统中 并非无需表的情况下 可能会受到这种索引的强制排序
这种方法的优势在于 当我开始扫描的时候 假设没有采用索引组织存储 当我沿着叶子节点扫描找到所有
正在寻找元组时,可以确保按照键定义的顺序获得页面 并排好序的顺序呈现
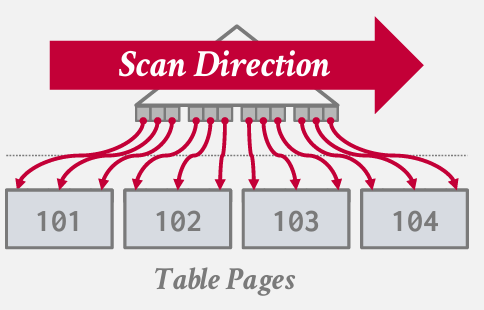
但如果假设我的缓冲区中只有一个空闲frame 并且如果我按照顺序扫描,按照索引输出的顺序获取页面 -- 可能会进行大量冗余的IO操作
假设你的缓冲区只有一个空闲帧(frame),这意味着每次只能加载一个页面到内存中。如果直接按照索引输出的顺序去获取页面,可能会导致大量的冗余I/O操作。例如,你可能先读取了一个包含感兴趣键值的页面,然后因为缓冲区空间有限而不得不丢弃这个页面来加载下一个页面。但随着查询的进行,你可能会再次需要之前读取过的那个页面,这就导致了不必要的重复I/O操作。
在这里 读取一页进行数据(因为那可能是我关注的key) 然后将其丢弃 获取下一页数据 但当我处理了更多的键后 我又会去读取之前处理过的同一页数据
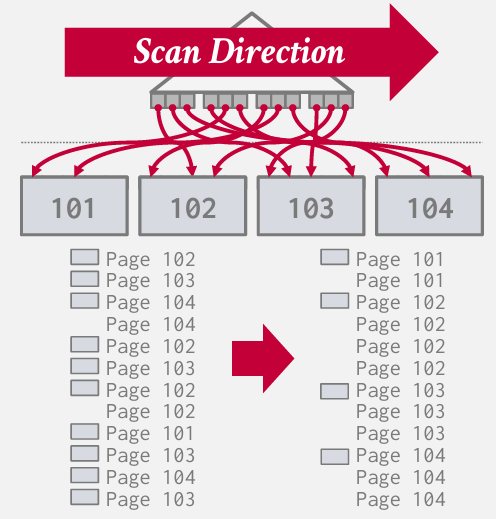
因此 非常简单的optimization是扫描叶节点时 不理解检查元组 而是找到他们后再进行检索
首先 先对叶子节点进行扫描 获取所有页面列表 然后根据pageID进行排序 接着依据此顺序进行检索
-为了减少这种冗余I/O操作,一种简单的优化方法是在扫描索引的叶子节点时不立即检查元组,而是首先收集所有需要访问的页面列表,然后根据页面ID对这些页面进行排序,最后依据排序后的顺序依次检索这些页面。这种方法的优势在于它可以最小化由于页面被多次读入和写出而导致的I/O开销,因为你可以规划一个最优的页面访问顺序,尽量减少磁盘寻道时间,并最大化利用缓冲区。
B+Tree Design Choices
许多概念源于 B+树圣经 Modern B-Tree Techniques | Foundations and Trends in Databases
Node Size
DB2可以修改 为不同的表 不同的索引 配置数据库page大小 根据硬件配置 为b+树节点 设置不同的页面大小
通常情况下 磁盘速度越慢 希望page越大 因为 最大化 顺序IO
merge threshold
某些系统实际上可以违反节点必须半满的要求
有时候不想频繁的分裂和合并 -- 可以暂时降低该阈值 -- 避免过早执行操作 -- 这就是为什么Postgres将b+树成为non-balanced B的原因 -- 因为可以违反这一要求
Variable-Length Key
Approach1: Pointers
尝试column storage -- 定长 -- 所以需要指针
store the keys as pointers to the tuple's attribute.
b+树中通常存储的是key本身 事实上key都比较大 而现在是这些键值的指针 也就32 或 64bit
bad: 不连续IO
- 当你到达一个节点并准备决定向哪个子节点移动时,你需要知道该节点中的每个键的实际值。如果这些键是通过指针存储的,那么你首先要做的是解引用这些指针以访问真实的键值。
- 一旦你获得了实际的键值,就可以将目标键与当前节点中的键值进行比较。基于这些比较结果(例如,是否小于、等于或大于当前键),你可以确定下一步应该向左、向右还是停留在当前节点(如果是等值查找)。
没有人这么做 -- 这种变体 叫T-Trees
Approach2: Variable-Length Nodes
使用变长节点 其中节点的尺寸可以在索引内变化 必须这么做 因为无法预置大小
我么希望每个节点中键的数量保持一致 但实际的情况是 我们未必有足够的空间在该节点中储存这些键
Approach3: Padding
padding(填充)是另一种处理方法 -- 在列存储中
很少有人这么做
Approach4: Key Map / Indirection
大多数人采用的方法实质上类似于分槽页方式 正如在页表中所见 其中只需要一个指针数组 这些指针位于你正在查看的页面内的偏移量或者指向另一个溢出页
Index node search
一旦到达节点 将其加在到内存中 如何查找关键字以决定向左还是向右移动 或者判断我们的叶节点是否已找到匹配项 我们需要决定如何进行这种匹配
Approach 1: Linear
最简单的方法 就是 进行一次线性扫描
就像一个大数组 不用考虑是否排序 只要从头开始扫描 知道找到要查找的内容

可以通过SIMD做的更好一些
SIMD代表单指令多数据 这是一类现代CPU上的指令 它是你能够基本拥有一个向量寄存器
你讲一堆数值存入其中 随后只需要一条指令即可进行操作
你可以将一组数字放入一个向量中 另一组数字放入另一个向量中 然后把它们相加 结果输出到另一个向量中
我们将在讨论查询执行时候 再讲这部分内容
SIMD(Single Instruction Multiple Data,单指令多数据)是一种在现代CPU上实现并行计算的技术。通过SIMD,可以在一个单独的指令周期内对多个数据点执行相同的操作,这大大提高了处理大量数据时的效率。
SIMD的工作原理
- 向量寄存器:SIMD利用了所谓的“向量寄存器”,这些寄存器能够存储多个数据元素。例如,您可以将一组数字放入一个向量寄存器中,另一组数字放入另一个向量寄存器中。
- 并行计算:一旦数据被加载到这些寄存器中,您就可以使用一条指令对所有对应的数据元素同时进行操作。比如,如果需要对两组数字进行相加操作,只需发出一条加法指令,它就会自动地把两个向量寄存器中的每个对应元素相加,并将结果存储到第三个向量寄存器中。
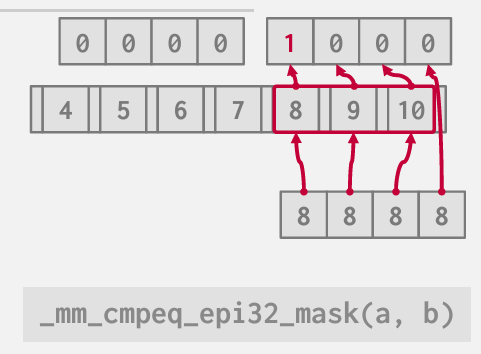
与其逐一查看每个键尝试找到8 可以选择SIMD内在函数
有四条车道 一条指令 就能并行对四个8进行求值 如果匹配就是1 不匹配就是0
依然是线性的 但是仍然可以批处理方式进行 因为硬件支持这一点
Approach2: Binary
二分查找 需要先排序

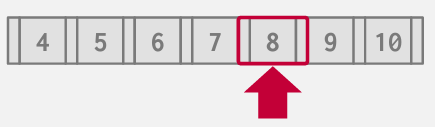
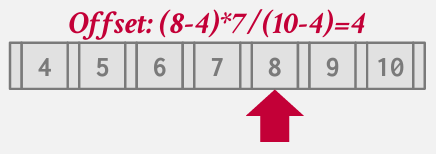
Approach 3: Interpolation
在学术界之外 没人这么做
interpolation search(插值搜索)
如果已知键值之间没有间隙 且始终保持单调递增的顺序 此方法便能奏效
通过一个简单的公式 便能跳转至所需偏移量
不过这是最快的方法 比二分和SIMD都快
Optimizations
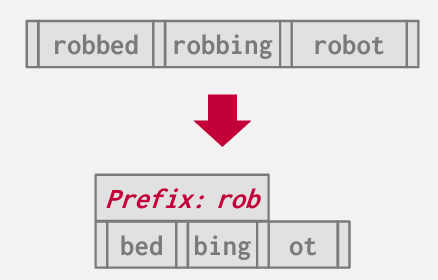
Prefix Compression
前缀压缩
我们可以识别出 将有一系列键值在字典序排列中非常接近 且他们的数据部分会有重叠
因此 我们不在存储完整的建副本 而是仅存储公共前缀 在例中为Rob 然后存储剩余的唯一后缀
deduplication
这里的想法是在一个node中可能会出现好多个相同的key 这里的想法是非唯一索引最终可能会在叶节点中存储同一键的多个副本。
叶节点可以存储一次键,然后维护一个包含该键的 Tuples 的“发布列表”(类似于我们讨论的哈希表)。
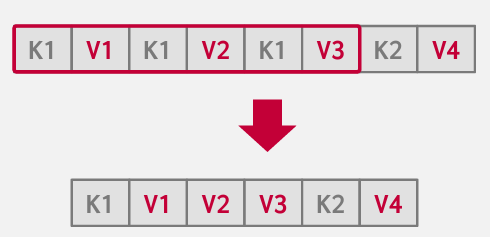
Postgres在Postgres15版本中添加了这一功能
效果相当显著
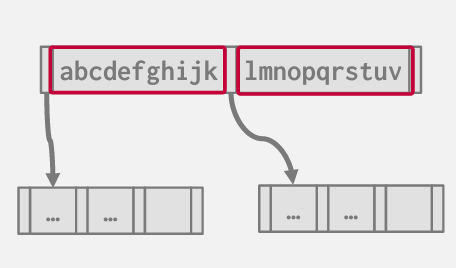
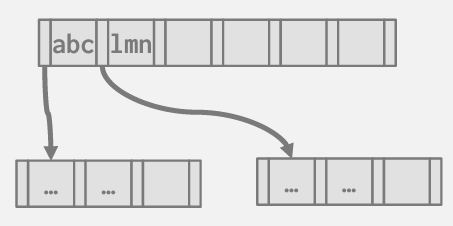
suffix truncation
由于内部节点无需精确复制键值 因为这些键值可能并不存在于叶节点中 我们或许无需存储完整的键值 我们只需要足够的关键字前缀来判断我们需要向左还是向右移动
在此例中 我拥有键值abc至k 以及lmno至v
实际上 此情形下真正关键的仅是这两串字符的前三个字符
因此我们的内部节点只需要存储我们需要决定向左还是向右走的最小前缀
当然挑战是 如果我插入一个可能位于他们之间的key 或许我得回溯并获得原始key 以确定前缀应该是什么
pointer swizzling
指针激活
常见的技术 -- 最大限度地减少在缓冲池表中所需的查找次数
我们遍历节点或树结构时 我们一再提及的“指针” 实际上是page id
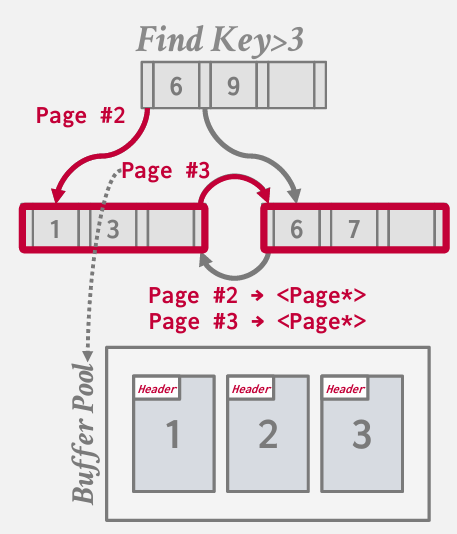
因此 我们访问page table 并查询 如果这个页面存在 给我 指向它的指针
向左--- 该结点中的值将是页码 这个时候需要进入缓冲池 -- 并指示给我第二页的指针
然后在底部沿着兄弟节点继续扫描 从page2 切换到 page3 得回到bufferpool
pointer swizzling的技术理念在于 如果将一个页面固定在缓冲池中 比如任何声明这个页面不可被置换 那么任何指向该固定页面的 也必须要固定 将其中内容替换为内存中的实际指针
因此 现在当我进行扫描 遍历我的树时 我不会去缓冲池哪里说 请帮我查找这个页面的信息 而是直接深入到下一层 因为已经有了指向目标位置的指针
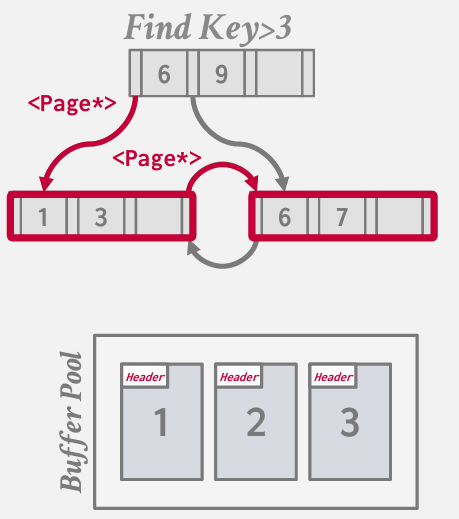
换句话说 node使用页面 ID 来引用索引中的其他节点。DBMS 必须在遍历期间从page table中获取内存位置 如果一个页面被固定在缓冲池中,那么我们可以存储原始指针而不是页面 ID。这避免了从 page table中查找地址。
在数据库系统中,节点之间的引用通常是通过Page ID实现的,这意味着当遍历一个树结构时,每个节点实际上包含的是其他节点的Page ID,而不是直接指向它们的内存地址。为了访问下一个节点,需要首先查询页表(page table),获取该Page ID对应的内存位置,然后才能进行访问。当一个页面被固定(即标记为不可置换出缓冲池)在缓冲池中时,所有指向该页面的引用都可以被“激活”——也就是说,原本保存的Page ID可以被替换为直接指向该页面在内存中的实际地址的指针
bulk insert
为了快速执行插入操作 最常用的技巧就是预先对所有数据进行排序 -- 以后会具体讨论这部分内容
当排好序之后 构建树的时候 就可以将key整理好 并将其作为叶节点分块展开 同时设置好兄弟指针 从下向上构建数据结构
这与上面演示时候的仅仅逐一插入key的情况不同 如果是一个一个插入的话 从顶部开始 逐层向下 不得不进行分裂操作
write-optimized b+tree
b+树的一大优势就是平衡性 所有操作都在O(log n)
但是挑战在于更新操作对于我们而说expensive 因为我们必须维持这种平衡性质
当有线程插入或删除数据时 他们可能抽到下签--可能要重新组织整个数据结构
因此 在理想情况下 我们找到一种方法 延迟对数据结构的更新 -- 累计这些更新 --可能仍需要重新组织事务 但一次性完成所有这些工作
这种情况下 写入可能会更快
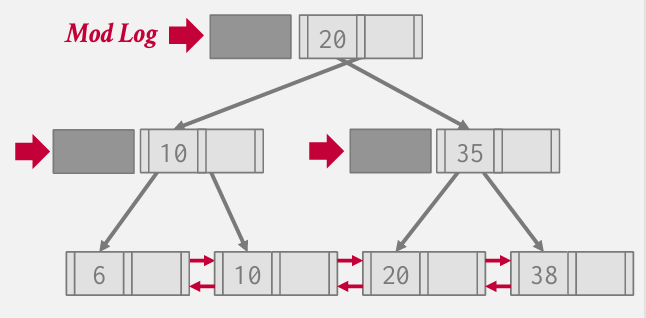
因此有一系列聚焦于所谓的写优化b或者b+tree Also known as Bε-trees.
基本思想是在每个单独的根节点和内部节点 都设计一个Mog Log(模数日志)
就像MySQL在对其他页面进行压缩时采用的方式一样 当有新的跟新到来时 并不会变更一路传播至叶子结点 而是会违反我们在b+tree中讨论的特性--节点必须存放实际值 我可以将我的条目插入到修改日志中
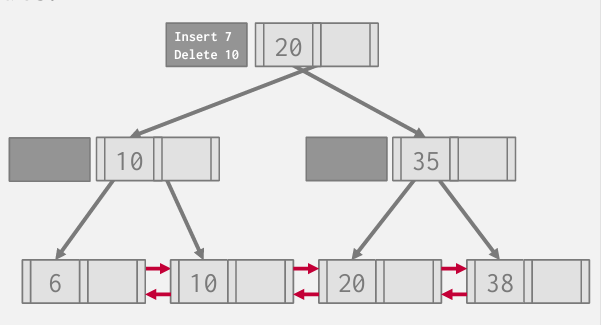
Insert 7 Delete10
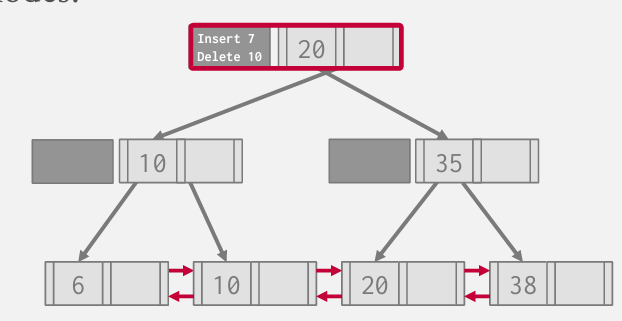
Find 10
在遍历过程中 会查看mod log 其实就会发现10已经被删除了
Insert 40 这个时候缓冲区满了 就要往下走一级
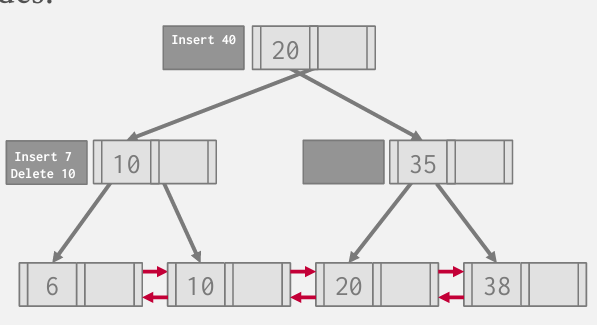
这可能会变慢--因为要去查mod log
但是不同的Bε-trees都会加上布隆过滤器 来确认
RockDB不需要这个 因为RockDB本身就是一个日志结构合并树