Lecture 20 Database Recovery
Overview
上一节课也提到,Recovery Algorithm其实有两部分
- Actions during normal transaction processing: 在事务正常运行过程中执行的操作,用来确保万一崩溃时可以恢复,我们讨论了WAL, Checkoutpoint等机制
- Actions after a failure: 当数据库崩溃的时候,确保ACID中的ACD
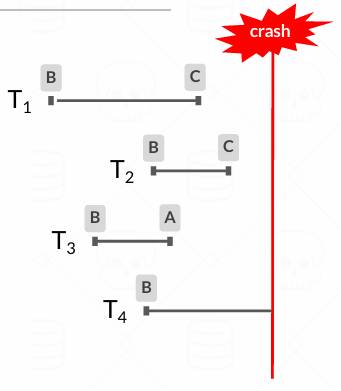
假设我们的系统采用的是上一讲锁探讨的高效的方式即Steal+No-Forece的方式
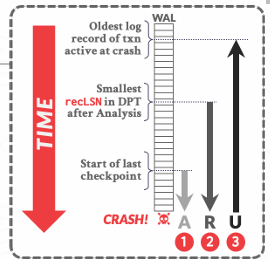
在这个图中时间线是从左往右移动的,我们需要去考虑这些不同的情况,T1和T2是已经明确Commit提交过的Transaction,但是可能有的更改崩溃时还在bufferPool未写入磁盘,那么就需要恢复到commit时的状态,重新提交 ;T3是明确abort的Transaction,但可能有的更改已经写入磁盘,我们需要撤销,T4是未执行完的Transaction,我们把他一同视为abort,要恢复到当时的状态
接下来我们要讨论的算法叫做ARIES(Alogrithm for Recovery and Isolation Exploiting Semantics), 是有IBM发现的,额那是一篇70页的论文
核心观点是要有下面这些组成部分
- Write-Ahead Logging: Last Lecture
- Repeating History During Redo(重演历史): 他的作用是执行看似多余的工作,但从逻辑上,它将进行多次遍历,第一次遍历是分析阶段,从某个点开始向前看,从检查点记录开始,并从此检查点记录读取所有日志向前推进(按照日志记录的顺序),在A传递完成后,它知道了崩溃时正在运行的所有事务,它弄清楚了每个事务是什么,知道事务是commit还是abort还是running,然后在redo传递中,返回到日志中,重新应用所有更改,最后将会undo所有lovser Transactions
- Logging Changes During Undo(Undo时也写日志): 如果在undo的时候又崩溃了,就要在下一次恢复的时候知道哪些undo已经完成,哪些还没做
today’s agenda
- Log Sequence Numbers: 我们需要一种方法在时间上来回穿梭,有时可能需要回溯,我们需要采取一些特殊措施,在日志中这种措施就是Log Sequence Numbers(日志序列号)
- Normal Commit & Abort Operation: 常规的提交和回滚操作
- Fuzzy Checkpointing: 不同的检查点技术,先介绍两种简单易懂的检查点方法,再介绍一种被广泛采用的方法叫Fuzzy Checkpointing
- Recovery Algorithm: 深入探讨实际的恢复协议
Log Sequence Numbers
随着课程的深入,我们未来需要给Log加入很多信息,但是后续都需要的一个信息是Log Sequence Number. 每条日志记录都带有一个全局唯一的LSN,作为时间的逻辑代理
这其实有点像我们在MVCC那样需要基于时间戳的信息,可以使用时间戳,也可能是某个全局数字的原子性增长……而LSN也是某个数字,为了效率,并没有采用时间戳,而是采用单调递增的变量。每当需要创建日志记录时,获取该变量,并将其作为LSN
日志记录将始终按照日志序列号的顺序创建,从而构成了所有变更视角下的时间历史,他其实解决了多个事务并发执行,数据库到底改了什么的追踪问题
系统中的多个模块都需要记录和追踪与它相关的LSN

每个日志记录都会分配一个LSN,都源于那个单一的全局计数器,但我们还需要跟踪大量的其他的事项
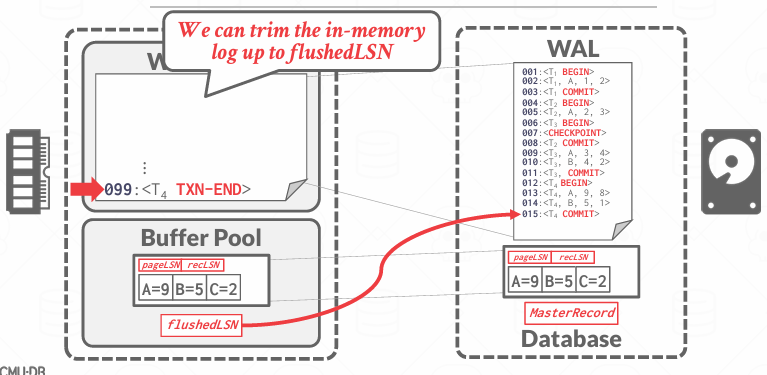
在DRAM中,我们跟踪一个flushedLSN的东西,表示已经刷新到磁盘日志记录中的最大的LSN的值,换句话说,大于flushedLSN的值的记录还未来得及刷新,也就是说,flushedLSN是日志安全落盘的进度标记,但是值得注意的是该信息存储在稳定的存储介质上,是必须在电源故障时能够幸存下来的信息
每个数据页还会包含一个字段叫做pageLSN,他是最近一次修改这个页所对应的记录的LSN
右边的长条是一个日志记录的图形表示,它存在于日志文件中,它们还拥有一小块空间成为日志缓冲池,日志记录被写入时,会按照顺序写入内存,最终会耗尽日志缓冲池并flush进入磁盘
而flashedLSN就是其中的边界,如果正在查找小于fulshedLSN的日志记录,我知道需要访问磁盘,如果大于 访问内存

如果仅仅用于一个pageLSN还不够,引入了flushedLSN后,我们还需要引入一些额外的内容
还有一个结构上的改动需要添加到页面上,那就是recLSN,他会追踪这个页自上次刷新以来第一次被修改时对应的LSN(最旧的)。所以说,逻辑上说,这意味着在recLSN和pageLSN之间的那些变更肯呢个尚未写入磁盘
我们跟踪另一种数据结构,我们将在内存中跟踪一种额外的元数据,被成为active transaction table. 它将持续跟踪哪些事务处于活动状态,以及当前的状态是什么,在其中也会有一个lastLSN即该事务创建的最后一个LSN,用于回溯undo日志(后面会看到)
最后一个需要的东西叫做MasterRecord,这是会一直保存在磁盘上的内容,记录最近一次成功的checkpoint的LSN,崩溃恢复时,恢复管理器首先要做的就是提取MasterRecord,该记录始终位于磁盘上的已知位置,redo可以从这里开始
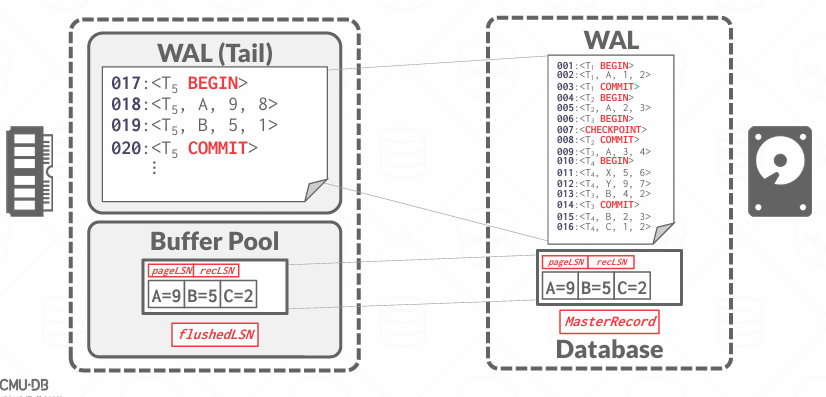
图中的信息是这样的
左侧存放的是DRAM的内容,右边存放的是稳定的内容
左边内存中WAL中的是日志的尾部,前面的内容已经刷新到了disk上的WAL,所有的日志都有了Log Sequence Number,单调递增
拥有一个带有若干值的page的bufferPool
当我们对页面进行修改时,就会更新页面里面的pageLSN,每次修改页面 都会获取新的LSN并更新到PageLSN,同时,页面中还包含一个recLSN,这是刷新进磁盘的最后一个日志记录
在内存中还有一个flushedLSN,指向磁盘中的WAL的日志尾部
磁盘中存在一个MasterRecord, 存放的是最近一次CheckoutPoint的位置
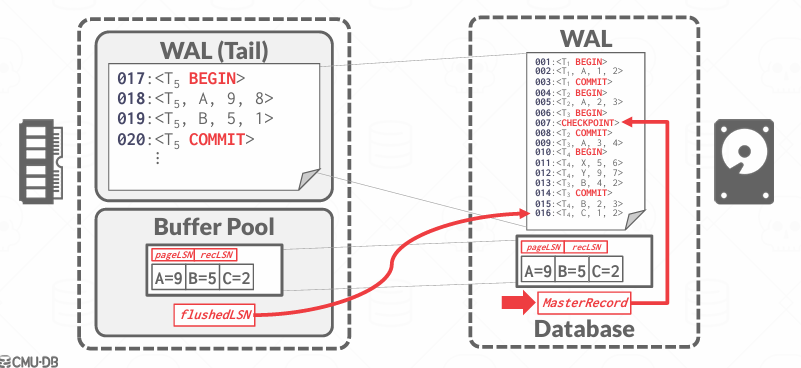
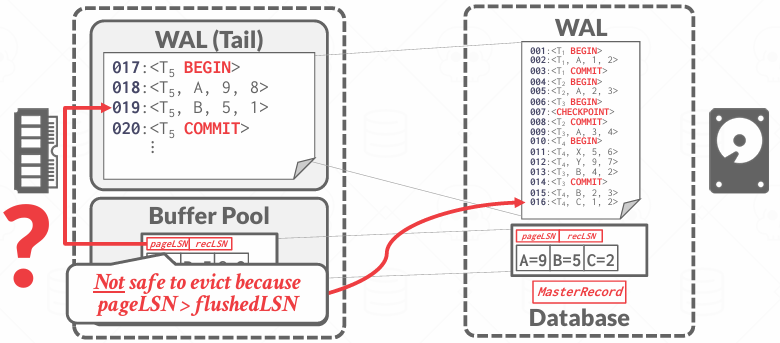
当要将页面刷新到磁盘上,日志最好位于磁盘上,我们将进行这一检查
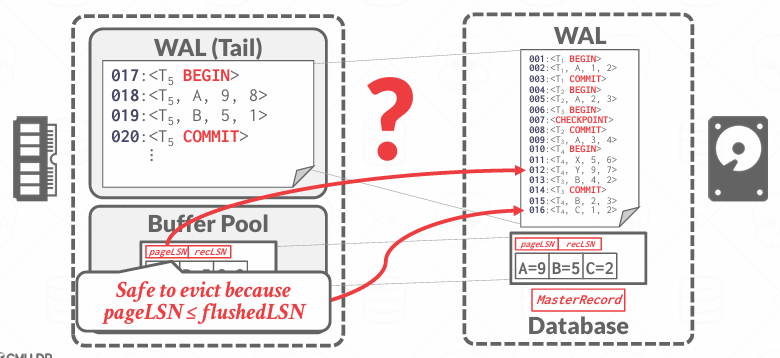
如果pageLSN < flushedLSN, 就意味着日志正存储在磁盘上 -- safe
如果pageLSN指向的是内存中的一个日志 -- not safe,必须先刷新日志进入磁盘才能将page刷新进磁盘,假设pageLSN指向了19,我们要先把前面的17,18一起刷新了 不会试图只提取19
Normal Commit & Abort Operation
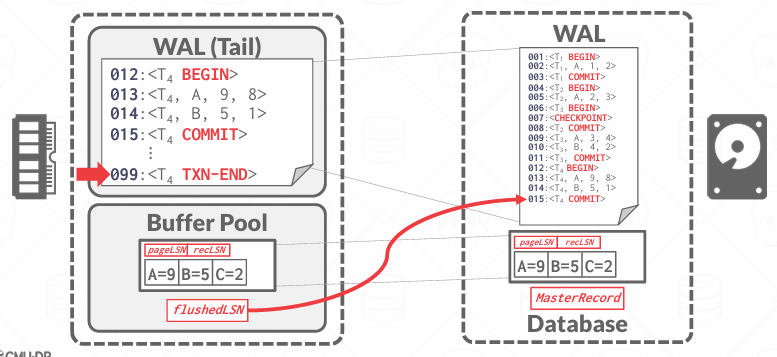
Transaction Commit
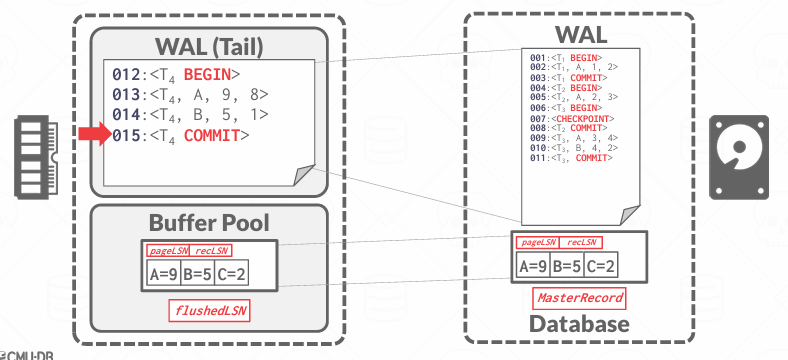
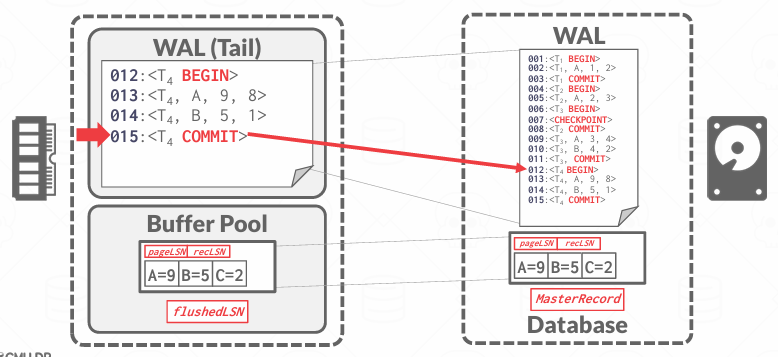
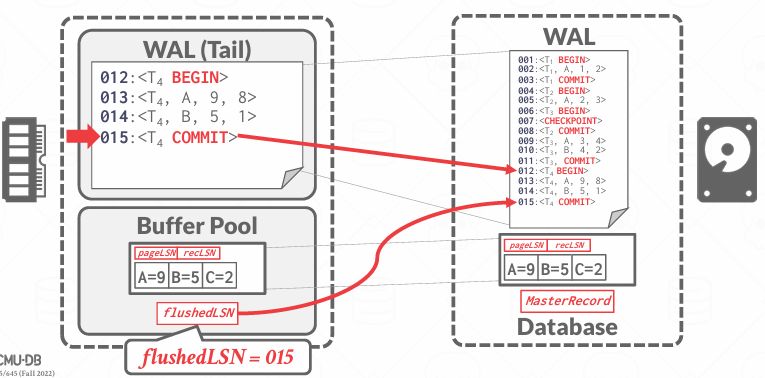
在事务提交的时候,数据库必须把一条COMMIT LOG写入WAL中,表示这个事务已经逻辑上完成,然后数据库必须强制将该事务所有的相关日志记录,包括COMMIT LOG本身,一起flush到磁盘,这是为了保证事务的持久性(Durability)
一旦commit成功,可以再写一条TXN-END日志记录,表示这个事务彻底结束,不会再有新的日志记录了,也就是说它告诉系统,不需要再关注这个事务了
值得注意的是,TXN-END对持久性保证不重要,所以它可以晚点写入磁盘,不要求立即flush
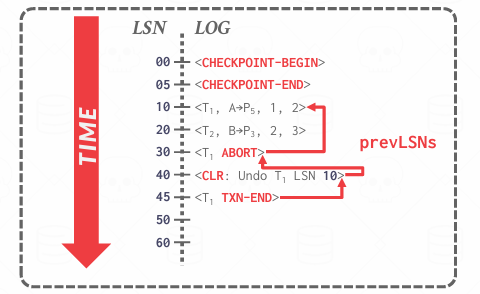
Abort Transaction
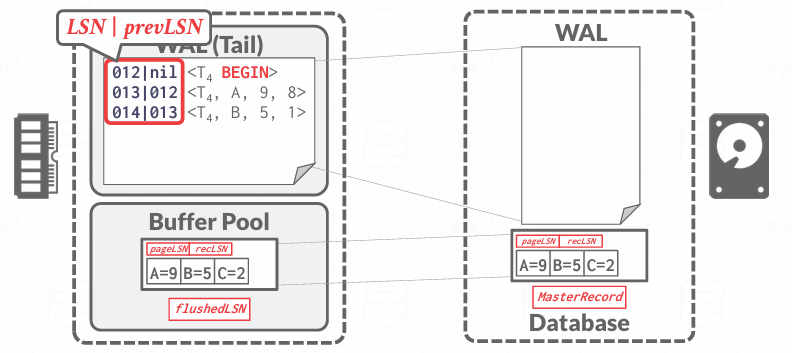
对于中止的事务,我们在日志记录中添加一个名为previousLSN的新字段,previousLSN是指该日志记录所属事务的前一条日志的LSN,是一个链式指针,把同一个事务的所有日志像链表一样串联起来。虽然previousLSN严格来说不是必须的,但它使事情更有效率。它的目的是,如果我在撤销(undo)T4事务, 没有previousLSN,就需要扫描整个日志就找属于T4的记录(因为可能会有很多事务交叉运行着),有了previousLSN,就像链表一条一条可以简单的往回走。
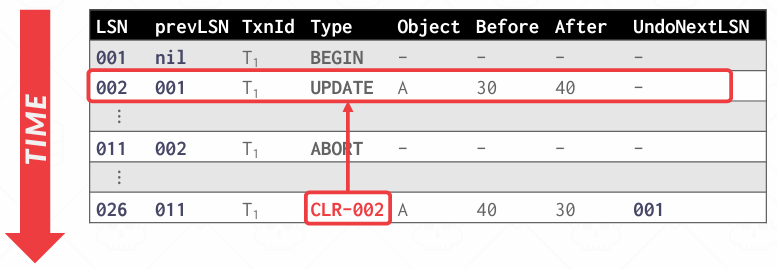
每撤销一条记录,系统会写一条新的CLR(Compensation Log Record, 日志补偿记录)到WAL中,CLR的作用是表明我已经撤销了这条日志,这样即使系统崩溃,也不会重复undo,不过CLR也会记录previousLSN,继续串起回溯路径

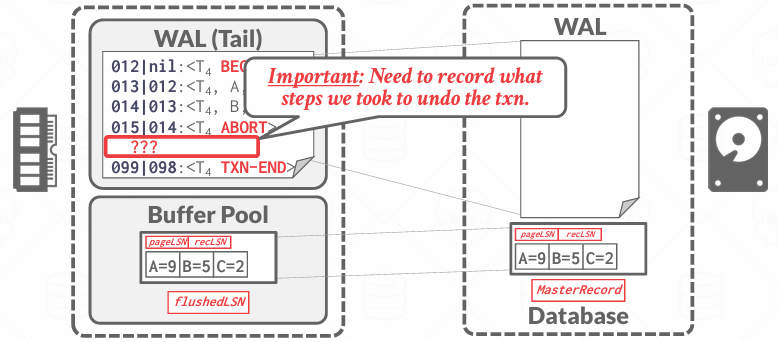
在这个例子中,没有流出中间的间隙。事实上可能不是这样一个接着一个的
当发生中止的时候,中止数据无需立即刷新到磁盘,最终我们会结束它,但从中止日志记录到结束日志记录之间,将会有一系列其他的日志记录,这些就是CLR(Compensation Log Record, 日志补偿记录), 这就是中止事务所需完成的工作
Compensation Log Record
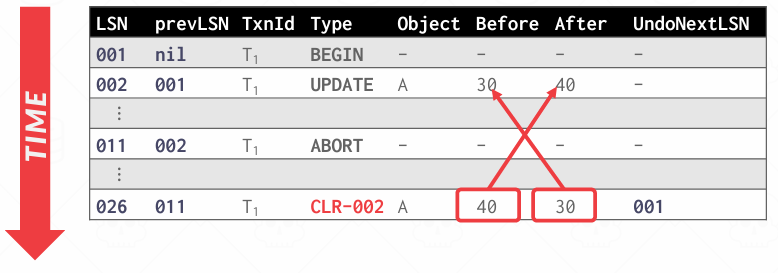
CLR是在undo某条update日志时写入的一条新日志记录,它记录"我已经撤销了那一条日志,并且具体做了什么",目的就是如果系统在undo过程中崩溃了,重启后知道哪些undo已经做了,哪些还没做
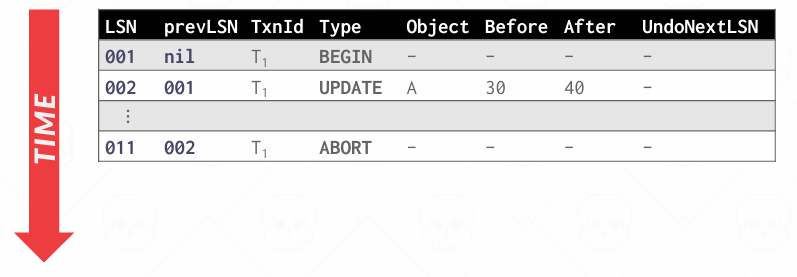
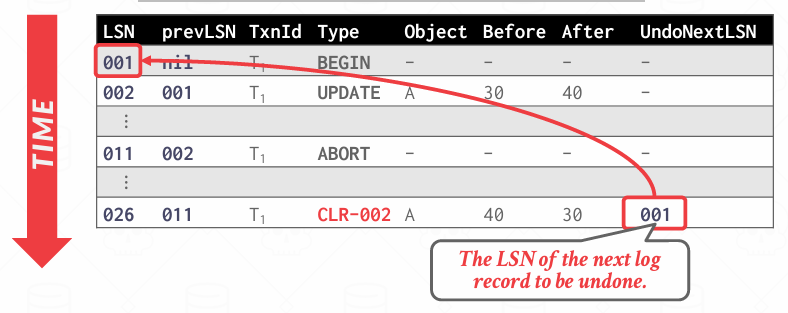
CLR包含的信息与基本上的update日志一样,包括哪个事务,哪个页面,修改了哪些值,不过它还存在一条新字段: undoNextLSN
undoNextLSN指向的是下一个需要被撤销的LSN,也就是当前undo过程中吓一跳的目标,也就是下一条待撤销的日志
Abort Algorithm
当事务决定abort时,数据库首先在WAL日志中写入一条ABORT记录,这表示日志不会继续执行,也不会提交
接下来事务倒序回溯该事务的所有修改操作的日志
for each update record, 要先写一条CLR补偿到日志中,然后把数据页恢复成旧值
撤掉完所有update记录后,写入TXN-END记录,表示事务彻底中止,释放该事务持有的所有锁
CheckPoints
正如之前所说,CheckPoints的主要目的是指示主日志记录,告诉您从何处开始恢复过程
Non-Fuzzy Checkpoints
执行检查点操作的最简单的算法就是Non-Fuzzy Checkpoints.
在这种算法中,数据库会暂停整个系统运行,不允许任何新写入或查询,这样可以确保在写检查点时,数据库状态是绝对一致的。具体来说就是组织所有新的事务就开始,等正在运行的事务执行完然后刷新所有脏页到磁盘
但面临的挑战在于,如果我的缓冲池有一百万页,那就需要写出一百万页的数据,世界可能会停滞很长一段时间
Slightly Better Checkpoints
算是Non-Fuzzy Checkpoint更为温和的版本,但仍然并不算好的处理方法
在Slightly Better Checkpoints中,仅仅暂停修改型事务(阻止事务获得写锁),但允许读操作继续
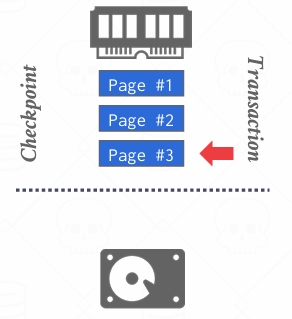
假设内存中有三个页面,当前运行的交易正在更新第三个,并且最终回去更新page1
检查点记录会一次访问页面1,2,3(通常情况下按照顺序逐一处理), 并将他们刷新到磁盘上
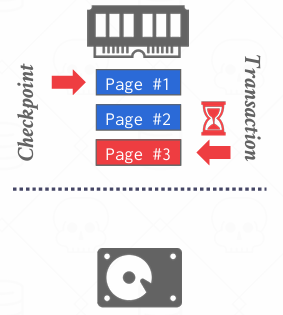
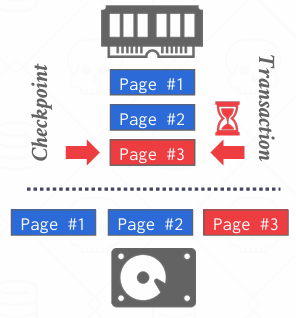
但一旦完成,检查点将会进入并跟新了第一页
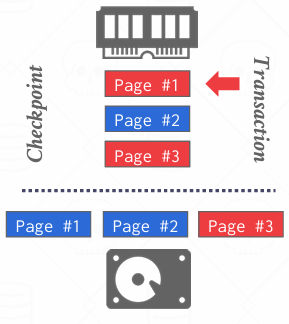
也就是说对于第一页来说并非一个完全的稳定的快照
稍有改进但并不仅人意,我们将采取一种措施,虽然会使回复协议略显复杂,却能大幅度提升检查点操作的速度,为此我们将引入两种数据结构
- Active Transaction Table(ATT, 活跃事务表)
- Dirty Page Table(DPT, 脏页表)
Active Transaction Table
用来记录正在运行的事务状态
每个事务对应在ATT表中都会记录txnID, status(包括R - Runing, C - Committing, U - Condiate for Undo),lastLSN(该事务最近一次日志记录的LSN,用于回滚或继续)
当事务写入TXN-END日志的时候,就表示彻底结束,从ATT中移除
Dirty Page Table
DPT用来追踪被修改但还没有写入磁盘的page,每个脏页一条DPT记录,包含pageID, resLSN(该page第一次变脏时的日志记录LSN)
为什么只记录第一次变脏的recLSN?
因为恢复时 redo 要从最早的修改开始,避免遗漏,所以 redo 阶段从所有 recLSN 中的最小值开始扫描
现在我们有了又有了一个更优的检查点
检查点日志记录将包含att和dpt的副本作为其中一部分
1. <T1 BEGIN>
2. <T2 BEGIN>
3. <T1, A→P11, 100, 120> ← T1 修改 P11,LSN=120(T1 Dirty P11)
4. <T1 COMMIT>
5. <T2, C→P22, 100, 120> ← T2 修改 P22,LSN=120(T2 Dirty P22)
6. <T1 TXN-END> ← T1 完全结束
7. <CHECKPOINT-BEGIN> ← 🟡 第一次检查点开始
8. <T3 BEGIN> ← T3 是在 checkpoint 之后开始的!
9. <T2, A→P11, 120, 130> ← T2 再次修改 P11,LSN=130
10. <CHECKPOINT-END>
ATT = {T2} ← T3不在ATT中
DPT = {P22} ← P11 不在 DPT 中!
11. <T2 COMMIT>
12. <T3, B→P33, 200, 400>
13. <CHECKPOINT-BEGIN> ← 🟡 第二次检查点开始
14. <T3, B→P33, 10, 12>
15. <CHECKPOINT-END>
ATT = {T2, T3}
DPT = {P11, P33}
Fuzzy Checkpoints
Fuzzy Checkpoints是现代数据库系统所广泛采用的技术,比non-fuzzy和slightly-better checkpoint效率更高,对运行中系统影响更小,是ARIES中的关键技术
Fuzzy Checkpoint 是指在生成检查点(Checkpoint)时,允许数据库继续运行并修改数据,不强行暂停事务,也不要求立即刷盘。 说白了就是 一边运行一边通过ATT+DPT记录着当前内容的状态,不打断业务 而ATT和DPT的内容将会是恢复时最重要的信息
我们在主记录中记录检查点,记录的是开始检查点的日志编号, 因为那才是检查点实际发生的位置,所以说扫描的时候是从ChECKPOINT-BEGIN开始扫描,所以如果只有检查点1的话能把T3算上
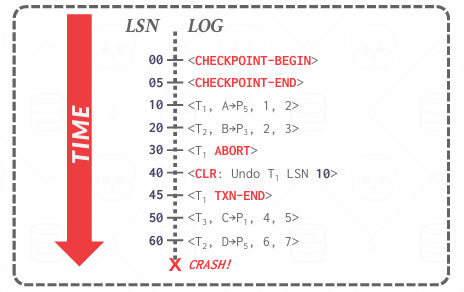
ARIES - Recovery Phases
前面提到过三个阶段,其实就是最一开始看的那张图
- Phase 1: Analysis
- Phase 2: Redo
- Phase 3: Undo
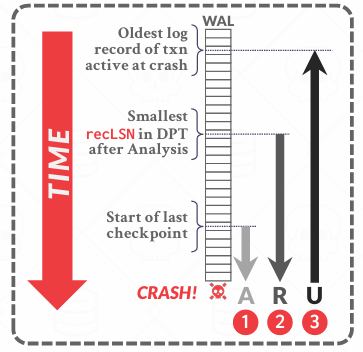
第一个阶段Analysis我们会找出系统崩溃时那些事务还活着(ATT), 哪些page是脏页(DPT). 具体就是从masterRecord的Checkpoint-begin开始扫描,如果不存在就从文件的第一个日志记录开始。 我们从起始检查点开始从上往下检查整个系统,直至最后一个日志记录,重建ATT和DPT,遇到还没有记录进去的(比如说上面例子的T3)就会更新ATT和DPT
第二个阶段Redo将会从DPT中最小的resLSN(最小的重做项,最早的日志记录)开始从上到下扫描WAL,这些操作是当时让bufferPool变脏的一些操作,重新引用这些更改让他变成原来的样子。当然图中这个地方可能会遍历一些没用的操作(包括没有进行更改的,还有A扫描过的一些部分),看似可以做一些优化,但是为了简化起见,都是直接扫描,全球都这样,尝试把这个优化到最优会使得本就复杂的协议变得更复杂,可能会隐藏细微的错误
第三个阶段Undo,撤销所有未提交的事务。有些事务还没有被commit其实有的内容就已经刷盘进去了,恢复的时候为了原子性,需要把当时没有commit的事务写入的数据给他回滚掉(但其实很大可能未来还是要把回滚的这个数据的改动再执行一次的,而且逻辑上其实我们按说未提交的本来就不能写入磁盘,只是为了效率给他写进去了),主要是利用前面说到的lastLSN倒着执行并写入CLR undo的
所以其实崩溃后内存中的所有的内容都没了,我们只能回到最后一个检查点,并以此为基础,一点点回到当时崩溃的样子
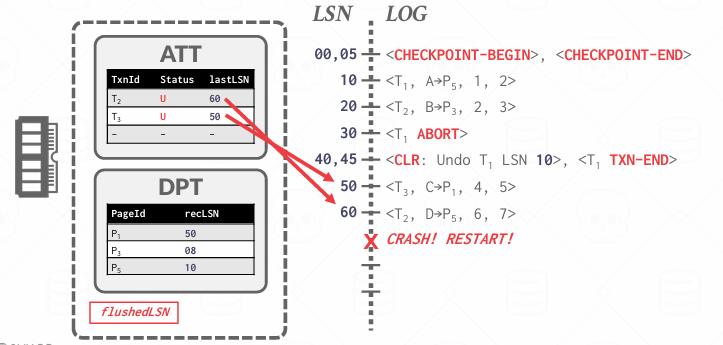
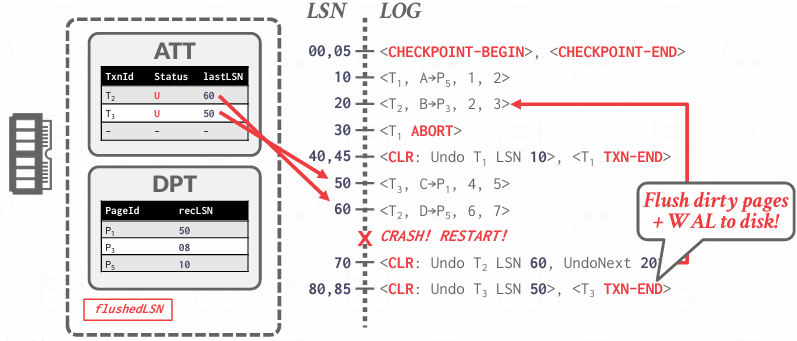
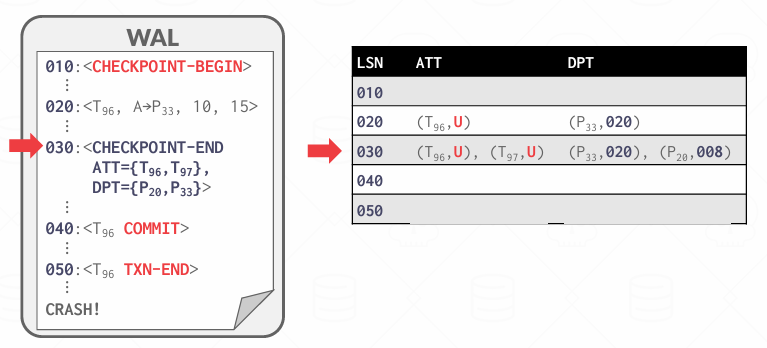
Analysis Phase Example
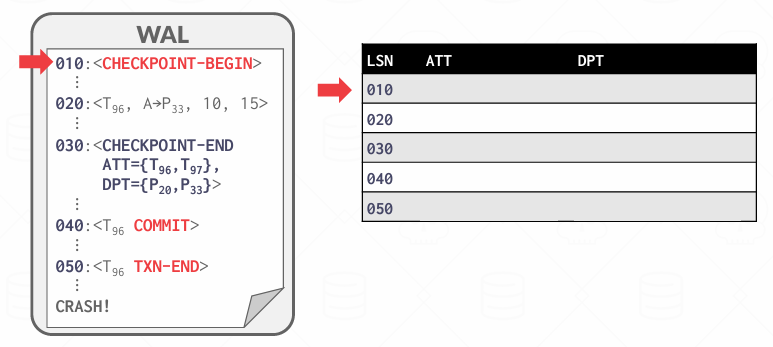
MasterRecord指向了010,然后我开始重建ATT和DPT
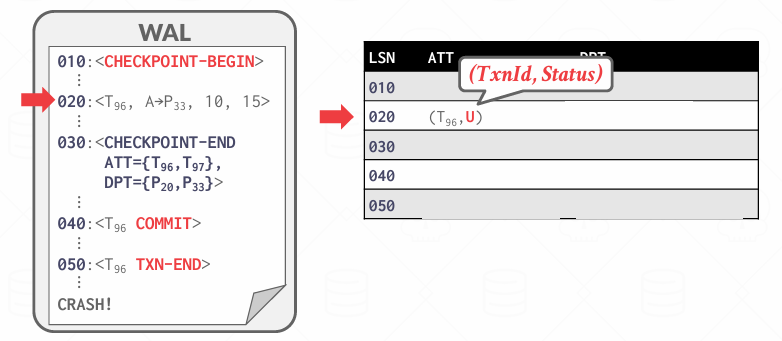
在这里第一次见到T96,但我不知道他的状态,可能后面会见到commit 可能会面会见到absort 现在还不知道,所以填了个U,因为如果没有commit的话 未来需要被撤销
然后再020中其实还对P33进行了更改,然后会记录recLSN
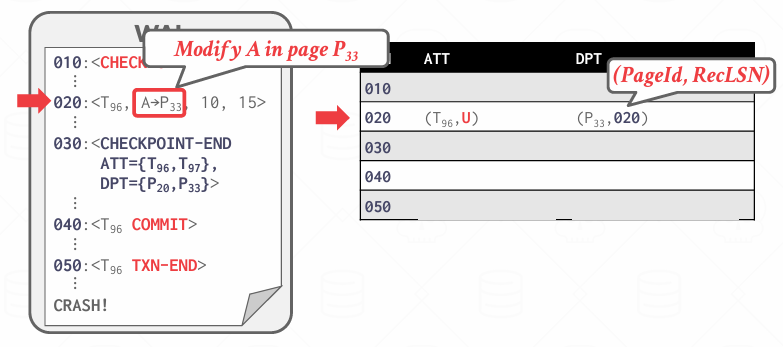
然后执行到030,把当时CheckPoint-begin时候的ATT和DPT补充上
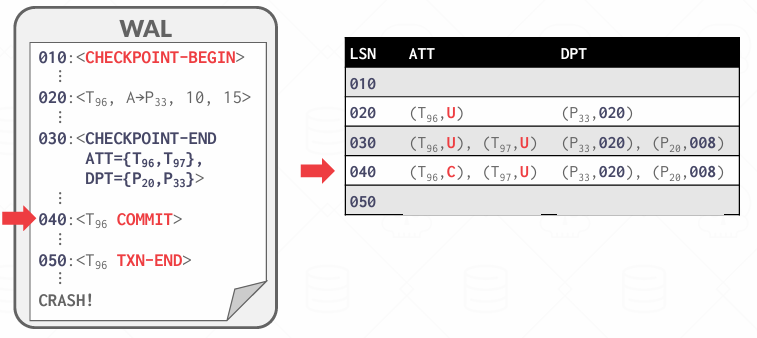
然后发现T96 Commit了 所以修改ATT中的状态
然后看到T96的TXN-END了,从ATT中移除
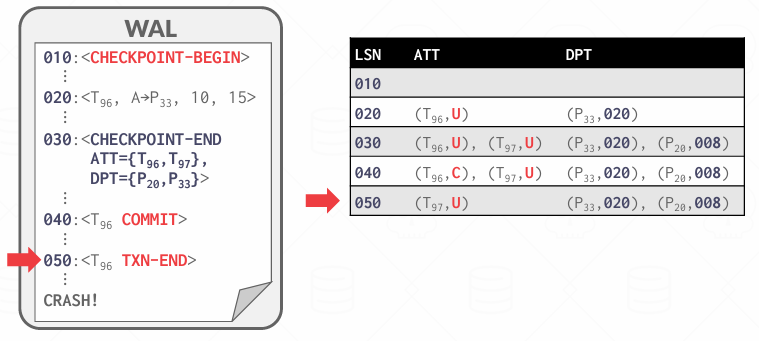
不过我觉着既然记录过P33 所以可能P33的recLSN可能会被更新成更早
这里P20 008之前的内容肯定已经在磁盘上了,08可能在磁盘上,不过可能P20的pageLSN是10,那说明008这条记录就不用看了 因为pageLSN是10意味着最后一次改是10 那么8其实就显得不重要了 因为最后变成10了
但是在分析阶段,只是收集信息
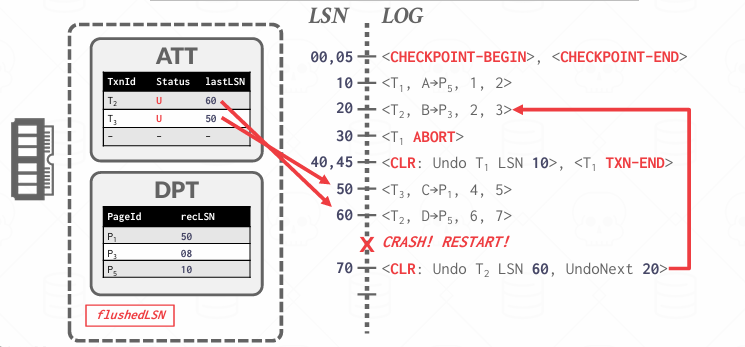
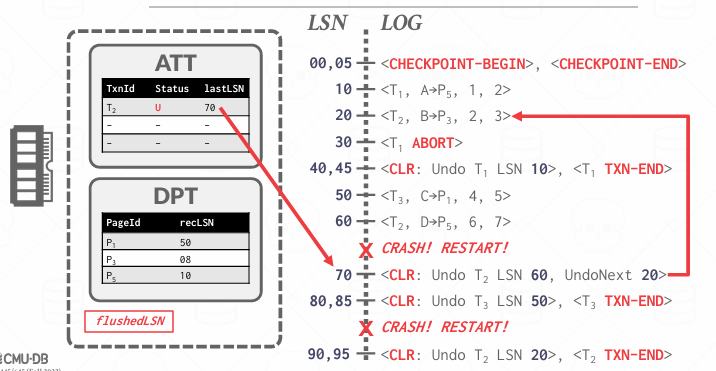
Redo Phase
从哪里开始Redo? -- 从DPT中最小的recLSN开始扫描,从上面的例子来说就是从008开始
对每条日志做判断是否需要redo?
- Affected Page,不需要Redo,因为没有脏过
- 该条记录的LSN < 对应页面的recLSN 不redo, 因为recLSN就是开始脏的第一条
- 与pageLSN比?
redo怎么做?
- 重放日志中记录的 修改(new value)
- 更新该页的
pageLSN = logRecord.LSN,表示这个页面已反映了此更改 - 不需要记录额外的日志,也不强制写盘!
这里其实我有一个疑问,既然pageLSN是最后一次更新的LSN,那本来就是脏的最新状态,为什么不从pageLSN开始找呢?而是从第一次脏的时候开始找?
pageLSN可能滞后?可是从那个时候开始扫描也能扫描到所有更新的日志啊 但可能resLSN就是干这个的
redo的时候从recLSN开始扫描,关注哪些page是dirty的,哪些还没落盘
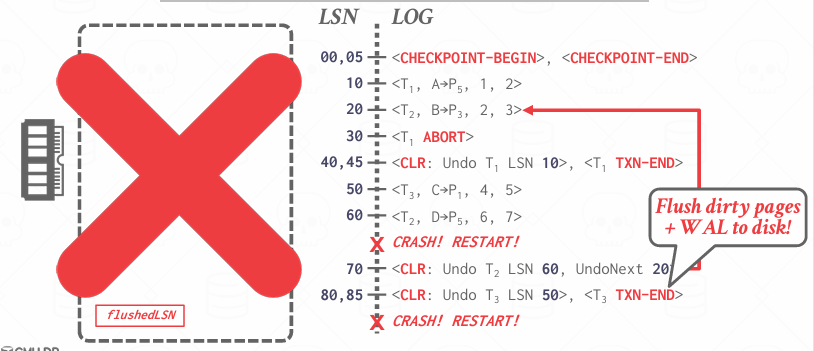
UNDO Phase
回滚状态是u的
REDO and UNDO Example