Lecture 21 Intro to Distributed Databases
Andy老师回来上课啦! 原来是感染了新冠病毒hhh 这都23年了还能感染新冠病毒的嘛
Overview
前面的lecture在高层次上构建了单节点数据库系统所需要了解的所有内容,在这个过程中,我们探讨了最底层,即存储层(storage layer), 我们讨论了如何将数据在内存中进行存取,如何实际运行查询,进行查询规划,将SQL转化为具体的物理执行计划,然后探讨了并发机制如何让多个事务在数据库上并发运行,以及恢复机制以便在崩溃的时候能够恢复
而从这个lecture开始,将基于迄今所学的东西,进一步探讨distributed database
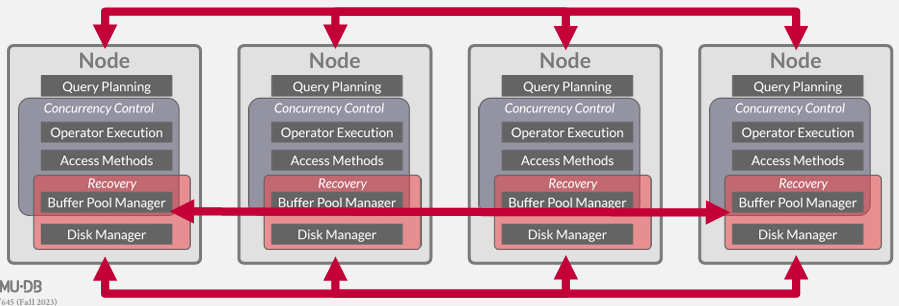
我们将要做出一系列关于如何让这些不同节点相互协调, 通信, 以及如何协作执行查询和执行操作的设计决策。我们可以让来自顶层的东西进行协调,并向顶层发送消息,也可以从底层开始,在构建分布式数据库系统时,将会面临不同的设计选择。
在CMU15445中,仅有3个lecture来讲解分布式数据库,属于此主题的速成课程
Parallel DBMSs vs. Distributed DBMSs
区分并行数据库系统和分布式数据库系统
并行数据库是那些节点在物理上彼此靠近的数据库,就像CPU的不同插槽和不同CPU核心之间那样子,他们通过某种高速互联进行通信,在同一架构内,就是一个巨大的机器。在并行数据库系统中,最关键的一点事,我们假设通信成本非常低,从一个worker向另一个worker发送信息仅需纳秒或微秒。我们还假设通信时可靠的,意味着如果我向另一个线程发送消息,该线程将会接收到该消息,除非存在任何软件错误
在分布式系统中,我们无法做出这些假设。因为节点和节点之间可能位于不同的区域 ,所以通信成本高昂,除此之外,通信并不可靠。TCP/IP协议有助于众多事务,确保数据包按序到达,但并不能保证我们发送的消息对方一定能收到或者不同顺序接收
this lecture从高层次概览分布式数据库的样貌以及需要注意的要点
next class OLDP分布式数据库
next class OLAP分布式数据库
CMU15-721全面聚焦于OLAP数据库
today's agenda
- System Architecture
- Design Issues
- Partitioning Schemes
- Distributed Concurrency Control
System Architecture
分布式数据库系统的系统架构,决定了CPU能直接访问哪些共享资源,从而影响CPU之间如何协调,数据库对象的存储方式和位置。
在设计分布式数据库系统的核心问题实际上内存和磁盘的位置在哪里,在任何给定时刻,谁有权读取和写入它
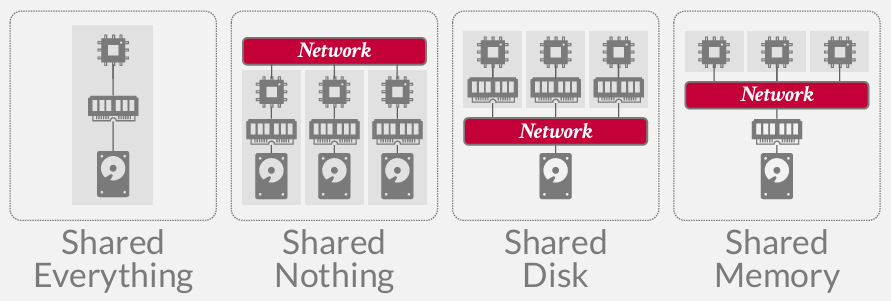
到目前为止,前面一直在讨论的,在数据库文献中被称为Shared Everything Systems: 单一节点,拥有本地磁盘,具备本地内存,数据库系统能够平等的访问所有的资源 -- Bustub(这门课的project), Postgres, MySQL
大多数人想到的分布式数据库系统实际上是Shared Nothing Systems: 存在单独的节点,这些节点拥有CPU, 并且CPU能访问内存,也能访问本地磁盘。但每当它需要与分布式数据库中的任何其他节点通信时,都必须通过某种网络协议进行,为了讨论,我们会假设是TCP/IP.
如今更常见, 尤其是云环境中,叫Shared Disk System: 仍然存在拥有CPU和本地内存的独立节点,甚至可能拥有直接连接的固态硬盘用于缓存, 但数据库的主要存储位置将位于某个共享磁盘上
还存在一种Shared Memory Systems: 磁盘和内存通过某种结构共享,而CPU节点或者说是数据库节点只能通过某种网络进行协调或通信,其实很像Shared Everything了 而且没人用这个 这种架构主要存在于高性能计算领域,旨在构建一个单一的非聚合内存池,所有节点均可通过内存池进行协调
Shared Nothing Systems
这里最关键的核心在于每个节点无法访问其他节点的内存和磁盘,只能通过某种网络(我们假设是TCP/IP)进行通信
传统观点认为,在Shared Nothing Systems中,这将带来更优的性能和效率,因为现在如果我将数据库分片或分区到这些不同的节点上,便可以分发查询,然后通过某种操作符进行类似并行执行的方式,将结果汇总起来,认为获得最佳性能是因为这不会受到其他任何节点的限制。但问题是需要与其他节点通信获取缺失的数据
挑战在于 由于存储在本地磁盘上的数据与每个节点绑定,因此扩展容量的时候需要重新分发数据到现在的所有的节点。确保一致性也将比较困难,因为每个节点都有自己本地的数据库副本,无法访问其他节点的内存,所以必须发消息询问他们对这次事务正在做什么操作

好多好多数据库都用了这种架构
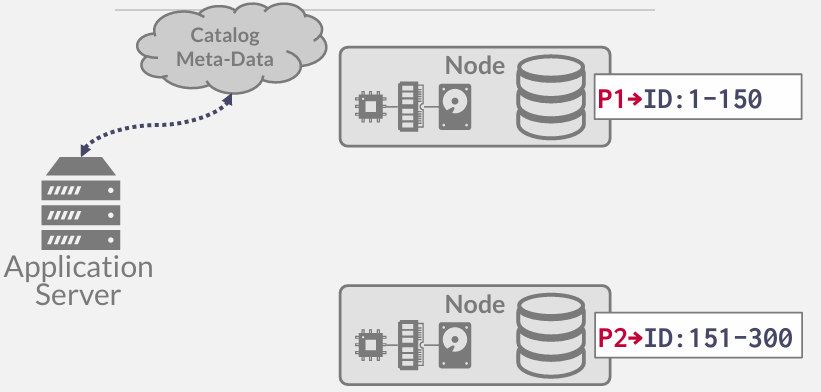
假设我们有一个两个节点的简单的Shared-Nothing架构的分布式系统 并且我们已经将一个单一表根据ID列(主键)的值进行了分区
确定前往哪个节点的方式,是通过某种目录(catalog)或者元数据(meta-data)的服务, 将其展示位云状是因为它可能位于实际节点上,也可能位于类似第三方外部服务的地方
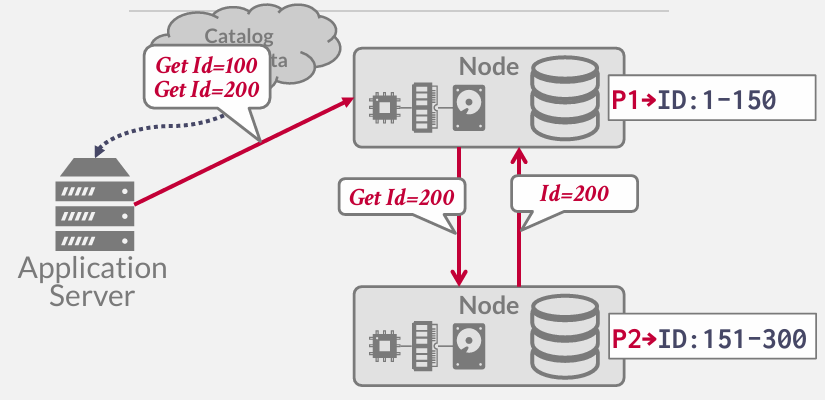
在查询过程中,可能只是发送给了顶部的节点,由顶部的节点决定怎么拿到这些数据
假设现在需要增加更多的服务器,因为延迟太高了,有太多的查询,需要横向扩展
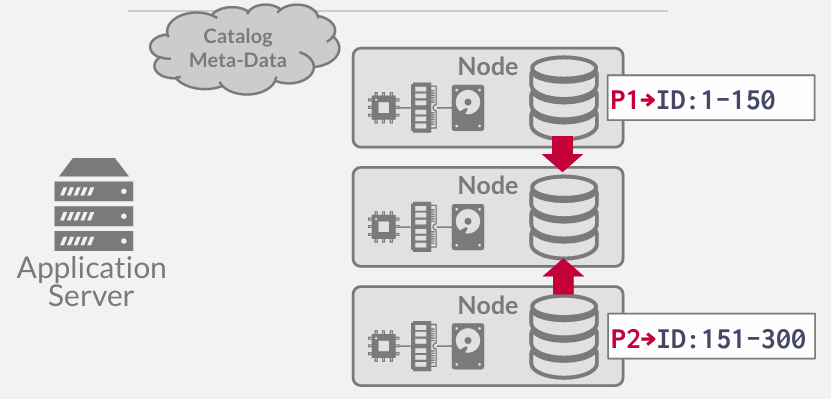
一开始这个节点并没有数据,当数据库启动的时候,需要从其他节点获取数据,以便填充磁盘并能够查询处理
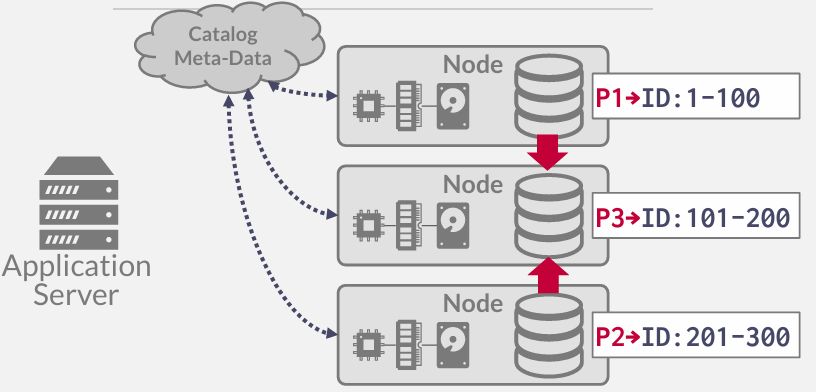
MongoDB能够实现自动扩展,如果您的分区或节点过热,系统可以自动分割范围,但MongoDB并未以事务安全的方式移动数据,因此 他们会进行复制操作,但无法保证当这种变化发生变更时,目录能够保持同步,所以会造成一个短暂的窗口期,目录尚未更新但是查询已经传到节点
所以分区的时候需要具有事务性
Shared Disk Systems
共享磁盘架构最早设计与20世界80年代,但基于此架构的许多系统并非取得成功,因为构造过程极其繁琐,但是云存储的出现改变了这一切
在这种架构中,需要去考虑在与一个shared disk进行通信,显然,要确保不能两个节点同时向同一份文件中写入数据
计算和存储分离 所以我可以很简单的加入一个new node,同样的也可以关闭节点,因为存储的东西在下面的shared disk上面
尽管上面我们的架构图中节点只有cpu和memory,但其实是可以有SSD作为缓存的,因为对象存储可能会有点慢
data lake就是指的这种架构(事实上我已经接触CMU15721的lecture01了 所以我清楚的知道warehouse, data lake, lakehouse都是什么样的架构),但是事实上dake lake中存数据不需要经过数据库管理系统

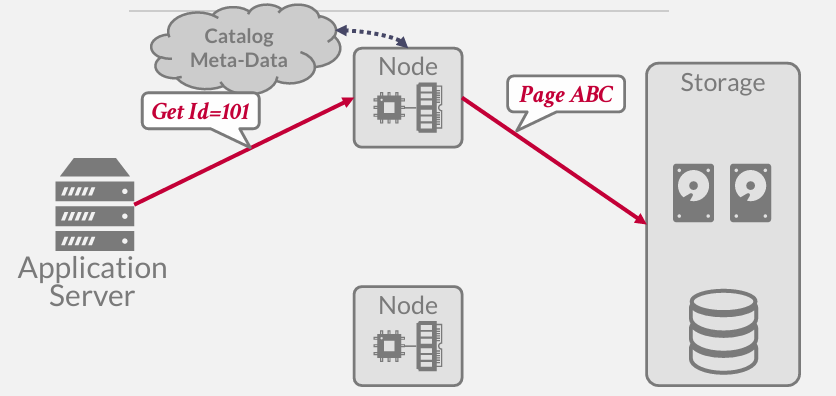
这里的过程是询问catalog数据到底在哪个桶里面 然后拿到数据返回给计算节点进行计算并返回
如果现在想增加新的计算节点,节点是无状态的,(也就是说数据库的主要存储位置不在计算节点上,而是在共享磁盘上,当然这些节点可能也会缓冲一部分页面的副本,因为每次在对象存储上查找信息都需要支付费用的) 所以不需要在节点之间复制任何数据
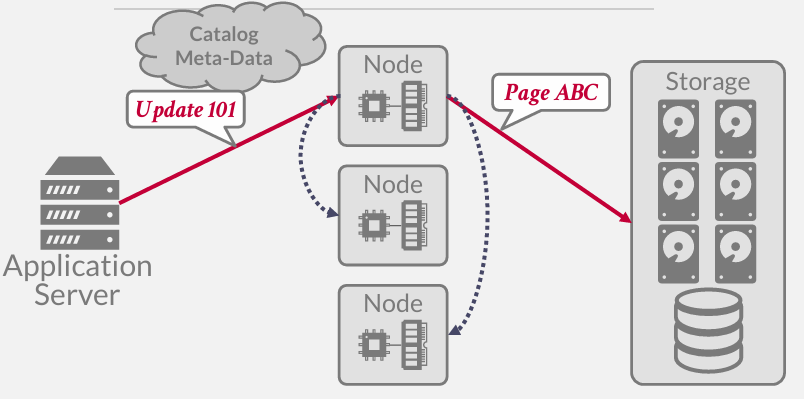
在更新的时候可能会通知其他节点,类似我知道你们手上有一份缓存的版本,无论当前的版本是否已经失效,都应该返回共享磁盘获取新版本