Project 3 Query Execution
Overview
我写的时候感觉还挺难的这部分 涉及到的类比较多 而且不知道为什么要这样操作……
在 Project 3 中,我们需要实现一系列 Executors(算子),以及为 Optimizer 添加新功能
- Task1:Access Method Executors. 包含 SeqScan、Insert、Delete、IndexScan 四个算子。
- Task2:Aggregation and Join Executors. 包含 Aggregation、NestedLoopJoin、NestedIndexJoin 三个算子。
- Task3:Sort + Limit Executors and Top-N Optimization. 包含 Sort、Limit、TopN 三个算子,以及实现将 Sort + Limit 优化为 TopN 算子。
- Leaderboard Task:为 Optimizer 实现新的优化规则,包括 Hash Join、Join Reordering、Filter Push Down、Column Pruning 等等,让三条诡异的 sql 语句执行地越快越好。
也正是因为CMU课程组搭好了大部分的架子 所以我们要去阅读弄明白里面的结构和联系😭
此外 Bustub提供了Live Shell: BusTub Shell
执行自己所写的bustub shell
# 确保在build目录下
./bin/bustub-shell
一条SQL语句的执行
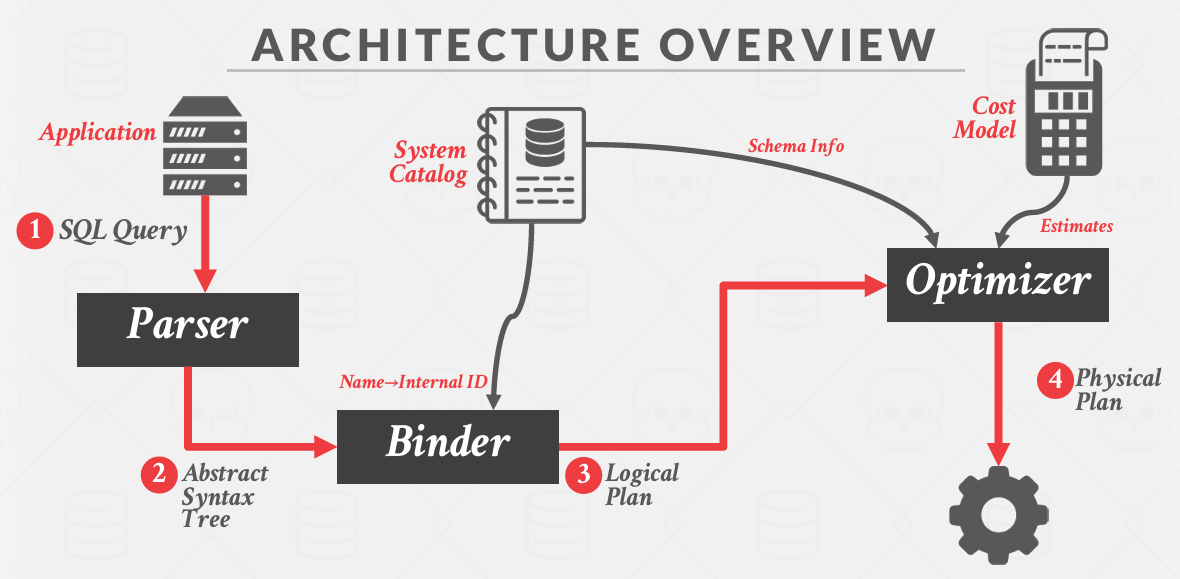
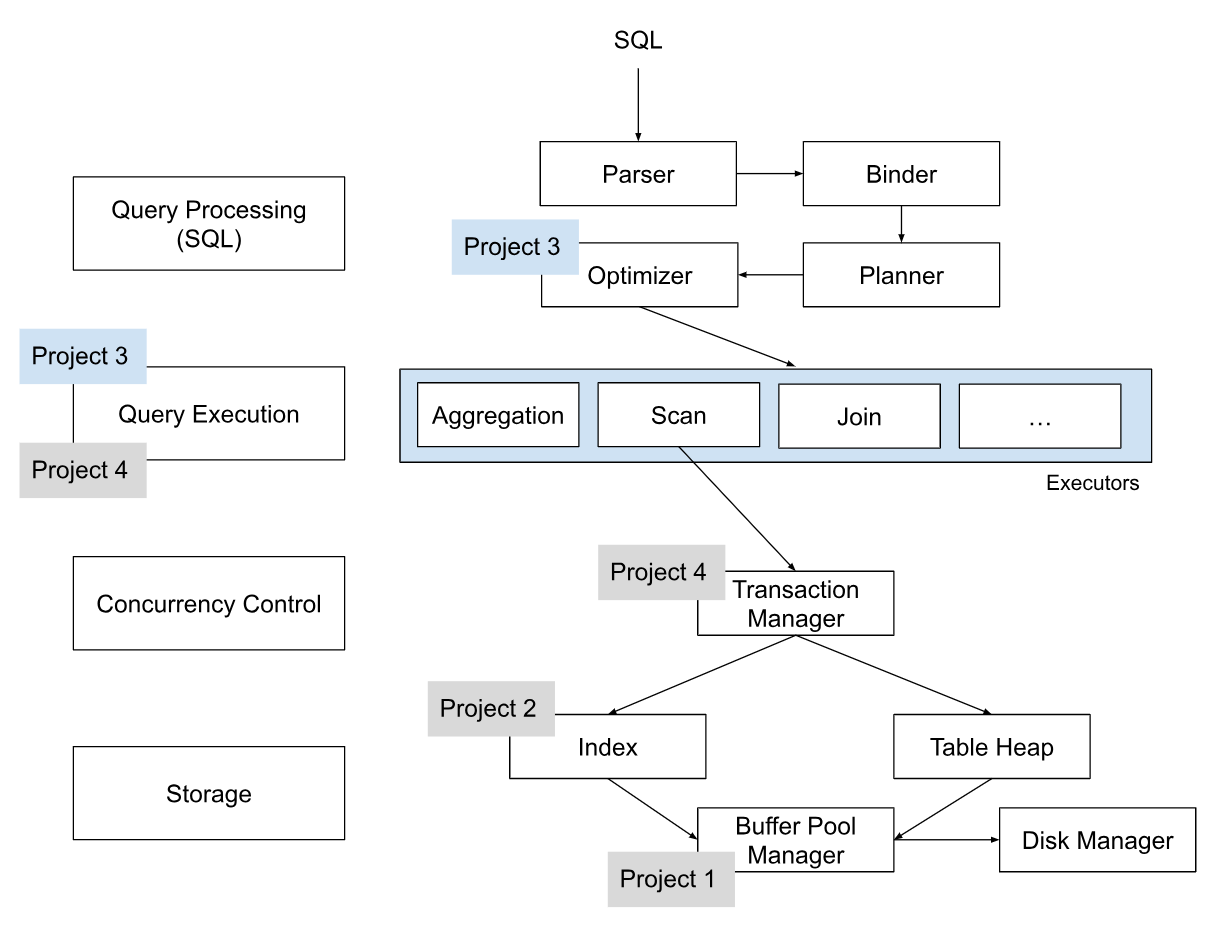
上面分别是Lecture 14 Query Planning & Optimization#Architecture Overview中的图和官方文档提供的bustub的架构图
一条SQL语句的执行将经历五个模块: Parser, Binder, Planner, Optimizer, Executors
Parser
一条 sql 语句,首先经过 Parser 生成一棵抽象语法树 AST。生成的过程有点像编译器和编译原理(但是我现在还没有学过编译原理的知识。Parser不是数据库的核心部分,一般都采用第三方库。在chi写的文档中或者在bustub的源码中发现bustub采用了libpg_query库将sql语句parse为AST
Binder
简单来说,Binder的任务就是将AST中的词语绑定在数据库实体上。比如:
SELECT name From student;
其中SELECT和FROM是关键字,name和student是标识符。Binder遍历AST,将这些词语绑定到相应的实体上。在bustub中实体就体现为各种C++类。最终的结果是一颗bustub可以直接理解的树 叫bustub AST
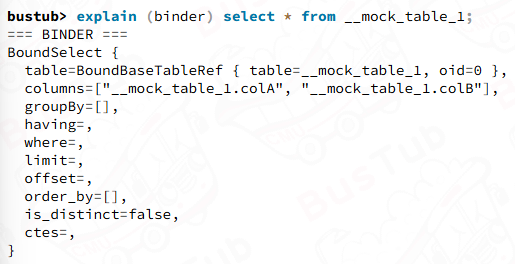
Binder会在catalog里面查__mock_table_1的信息,将__mock_table_1绑定到具体的实体表上(table_oid=0)。与此同时,将 select * 中的 * 展开成可以查到的所有列。这就完成了整个 binding 的过程。
Planner
Planner 递归遍历 Binder 产生的 BusTub AST,产生一个初步的查询计划

其实生成的原理的查询计划是
其实使用了三个算子
- NestedLoopJoin算子
- Projection算子
- Seqscan算子
这里注意一个地方,我们在Lecture 14 Query Planning & Optimization中学的其实是planner生成logical plan node,然后通过optimizer做多步优化产生physical plan node。但是 BusTub 只是个教学项目,所以我们只有 physical plan node. 比如说在上面这个例子中,planner直接join plan成了NestedLoopJoin.
Optimizer
对Planner生成的计划进行优化 生成优化后的最终查询计划

Optimizer 主要有两种实现方式 分别在Lecture 14 Query Planning & Optimization#Rules和Lecture 14 Query Planning & Optimization#Cost-based Query Optimization提到了
- Rule-based. Optimizer 遍历初步查询计划,根据已经定义好的一系列规则,对 PlanNode 进行一系列的修改、聚合等操作。例如我们在 Task 3 中将要实现的,将 Limit + Sort 合并为 TopN。这种 Optimizer 不需要知道数据的具体内容,仅是根据预先定义好的规则修改 Plan Node。
- Cost-based. 这种 Optimizer 首先需要读取数据,利用统计学模型来预测不同形式但结果等价的查询计划的 cost。最终选出 cost 最小的查询计划作为最终的查询计划。
Bustub 的 Optimizer 采用第一种实现方式

还是上面的例子,在经过Optimizer后,事实上将NestedLoopJoin在optimizer中改写成了HashJoin或者NestedIndexJoin. 对应的是哈希表和b+tree两种形式 在lecture中都讲过 Lecture 07 Hash Tables Lecture 08 Tree Indexes
Executor
在拿到 Optimizer 生成的具体的查询计划后,就可以生成真正执行查询计划的一系列算子了。算子也是我们在 Project 3 中需要实现的主要内容。生成算子的步骤很简单,遍历查询计划树,将树上的 PlanNode 替换成对应的 Executor.
算子的执行模型也大致分为三种 Lecture 12 Query Execution Part 1中提到的
- Iterator Model,或 Pipeline Model,或火山模型。每个算子都有
Init()和Next()两个方法。Init()对算子进行初始化工作。Next()则是向下层算子请求下一条数据。当Next()返回 false 时,则代表下层算子已经没有剩余数据,迭代结束。可以看到,火山模型一次调用请求一条数据,占用内存较小,但函数调用开销大,特别是虚函数调用造成 cache miss 等问题。 - Materialization Model 所有算子立即计算出所有结果并返回。和 Iterator Model 相反。这种模型的弊端显而易见,当数据量较大时,内存占用很高。但减少了函数调用的开销。比较适合查询数据量较小的 OLTP workloads。
Vectorization Model. 对上面两种模型的中和,一次调用返回一批数据。利于 SIMD 加速。目前比较先进的 OLAP 数据库都采用这种模型。
Bustub采用的是火山模型
此外,Lecture 12 Query Execution Part 1也提到了算子的执行方向也有两种:
- Top-to-Bottom. 从根节点算子开始,不断地 pull 下层算子的数据。
Bottom-to-Top. 从叶子节点算子开始,向上层算子 push 自己的数据。
Bustub 采用 Top-to-Bottom和Iterator Model
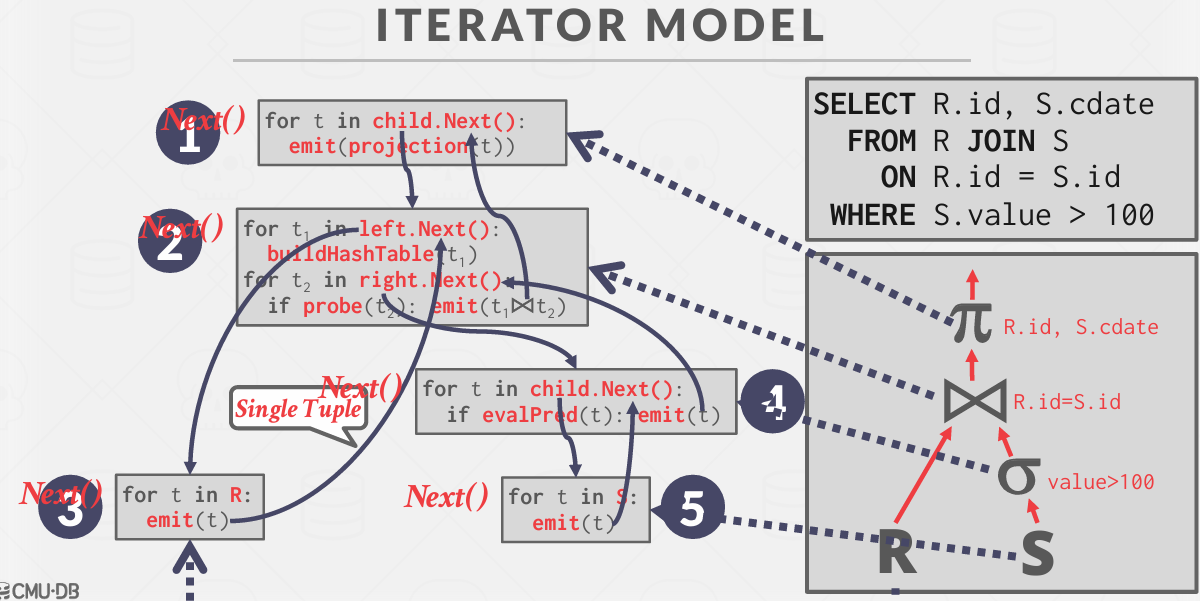
Executor
executor 本身并不保存查询计划的信息,应该通过 executor 的成员 plan 来得知该如何进行本次计算,例如 SeqScanExecutor 需要向 SeqScanPlanNode 询问自己该扫描哪张表。
当执行器需要从表中获取数据时,如果查询计划中包含索引扫描操作,执行器会通过索引来快速定位数据。
- 执行器根据查询计划确定需要使用的索引。获取索引的元数据,包括索引键的模式和表列的映射关系。
- 根据查询条件和索引的元数据,构建索引键。这通常涉及到从查询条件中提取列值,并根据索引键的模式进行转换。
- 调用索引的
ScanKey方法,传入构建好的索引键和一个结果 RID 向量 - 索引会根据键值查找对应的记录,并将找到的 RID 存储在结果向量中
- 使用结果向量中的 RID,从缓冲池中查找对应的页。如果页不在缓冲池中,则从磁盘加载到缓冲池。
- 从页中读取数据并创建
Tuple对象
整体结构
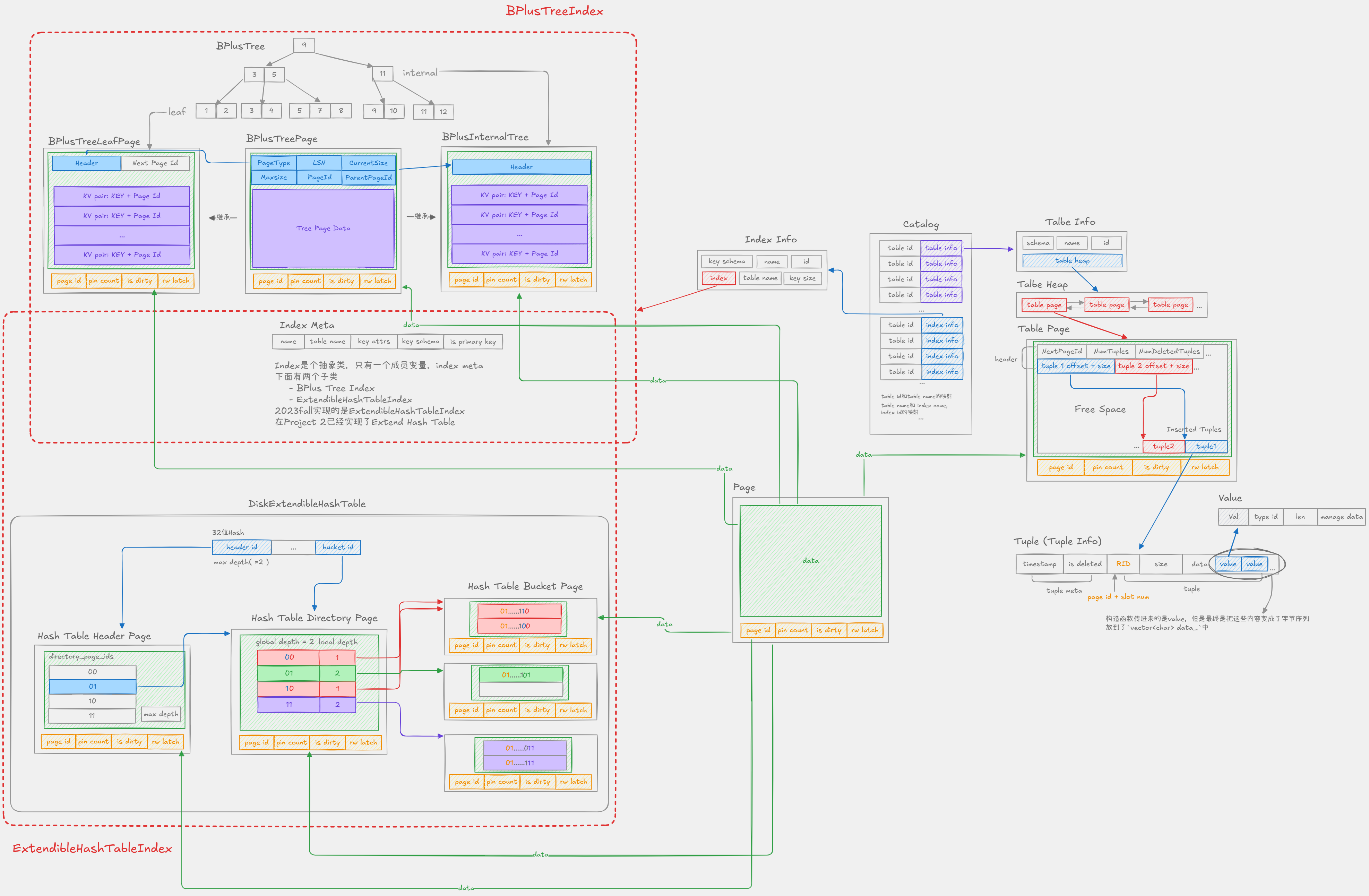
Catlog
BusTub有一个Catlog。Catlog提供了一系列API,例如CreateTable(), GetTable(), CreateIndex(), GetIndex()等等。Catlog事实上是两部分:
- 一部分是维护了table的hashmap,保存了table id和table name到table info的映射关系, 其中table id是由Catlog在新建table时自动分配的, table name由用户指定;事实上在源码中存的是一个关于table id和table info的哈希表,和一个关于table id和table name的哈希白哦
- 另一部分是维护了index的hashmap, 保存了index oid到index info, index name到index info的映射关系
- 除此之外还存了table name -> index names -> index identifiers的映射
为什么维护了table和index: 因为我们操作记录的时候,比如说插入新记录,不仅需要将记录插入到表中,还需要将相应的索引条目插入到索引中
Table Info
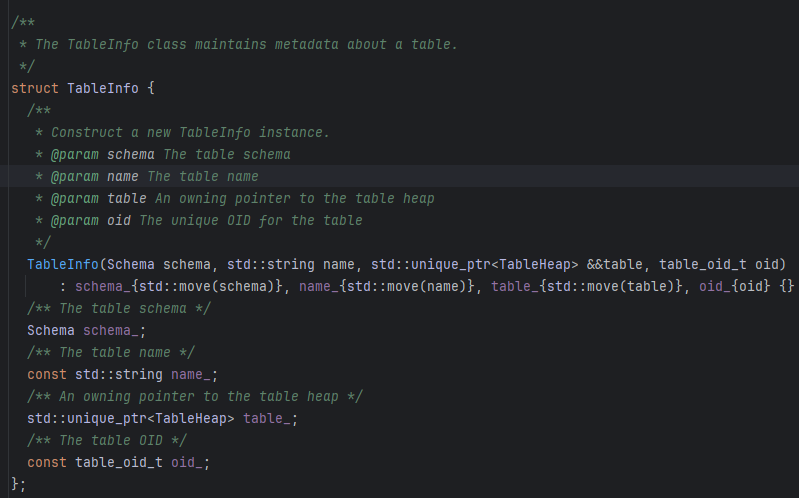
table info中包含了一张table的metadata, 其中由schema, name, id和指向table heap的指针。系统的其他部分想要访问一张表的流程是要先使用name auto GetTable(const string &table_name) const -> TableInfo *或者idauto GetTable(table_oid_t table_oid) const -> TableInfo *从Catalog得到table info, 然后再访问table info中的table heap(table heap是管理table数据的结构,后面会提到 这其实也就是Lecture中提到的堆文件结构!)
其实一开始我不太理解schema是什么意思,看源码其实能看到 schema实际上就是Tuple中column的格式 表示这张表有哪几列
Table Heap
table heap是管理table数据的结构,包含 InsertTuple()、MarkDelete() 一系列 table 相关操作
其实看源码不难发现事实上table heap并不本身存储tuple的各种数据,tuple的数据存在了table page中,而table heap存储的是table page的page id, 其中包括first page id和last page id,并通过Project 1的buffer pool和Project 2中实现的PageGuard来操作的tuple。
Table page
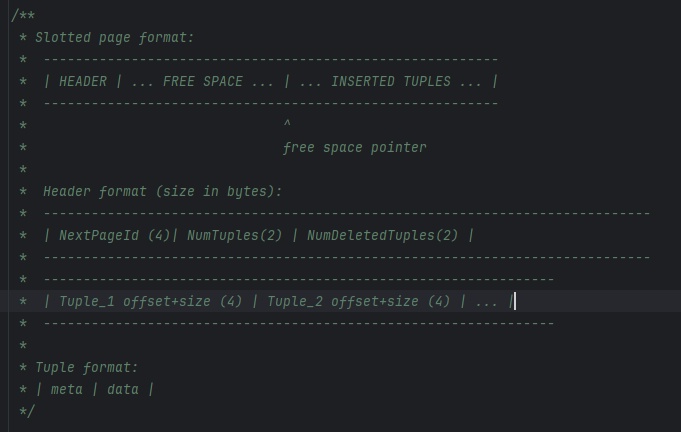
table page是实际上存储table数据的结构,其实从源代码中官方给的注释能看出来,这其实是一个典型的在Lecture 03 Database Storage Part 1#page layout提到的 堆文件存储格式+槽数组管理的页面。有三部分组成,一开始的Heads,中间的Free Space和从后往前存的Inserted Tuples
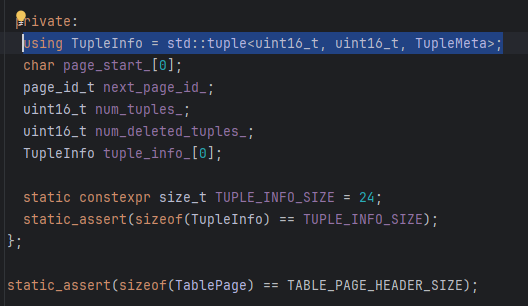
Tuple 和 Tuple Meta
Tuple是由RID, size, data组成的
每一个tuple都由RID唯一标识,RID 由 page id + slot num 构成。data 由 value 组成,value 的个数和类型由 table info 中的 schema 指定。Tuple(vector<Value> values, const Schema *schema); 其中 value则存了内容本身和类型。虽然在构造函数中传入的是values和schema,但是最终是把这些内容变成了字节序列放到了vector<char> data_中
其实bustub中Tuple Meta和Tuple是两部分(源码中),TupleMeta 是独立的,在 TablePage 的 slot 中与 Tuple 数据并排存储,不是 Tuple 的成员
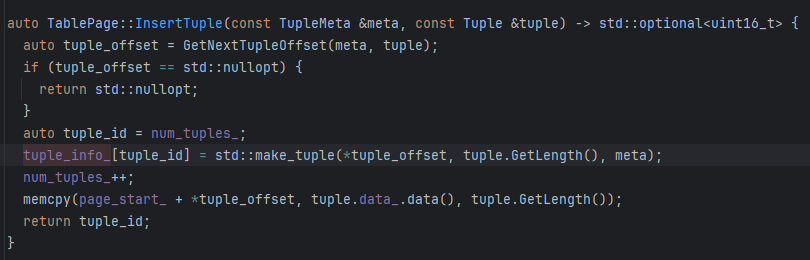
Index Info
在Catlog中 ,可以获取到一个表对应的所有IndexInfo,IndexInfo中包含着索引的信息,包括name, key schema, index oid, index, key size... 其中比较重要的是key schema是构建索引的列的结构, index_ 是个智能指针,指向的是真正的索引Index类对象
Index
Index类只有一个成员变量就是 Index meta.
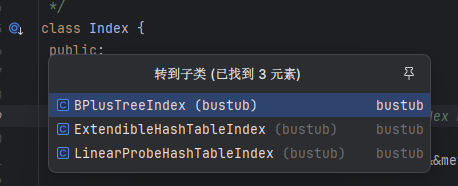
Index类实际上就是一个抽象类,提供了三个虚函数,在bustub中,我们的索引有两种,一种是hash index,一种是b+tree index。所以Index实际上有两个子类,一个是ExtendibleHashIndex, 一个是 BPlusTreeIndex. 在fall2023的课程中,我们用的是ExtendibleHashIndex,用的是我们Project2实现的可扩展哈希
Extendible Hash Index
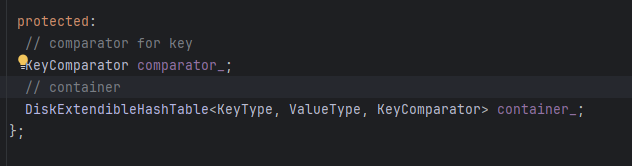

能看到在这里正式和Project2实现的DiskExtendibleHashTable建立起来了联系,其实Index也是个Page不是嘛 这里就在DiskExtendibleHashTable的Insert等操作中正式用了Project2 中实现的ExtendibleHTableHeaderPage,ExtendibleHTableDirectoryPage, ExtendibleHTableBucketPage
Task 1 - Access Method Executors Executors
SeqScan
首先我们应该弄明白源码所给出来的SeqScanExecutor类中的成员变量和函数
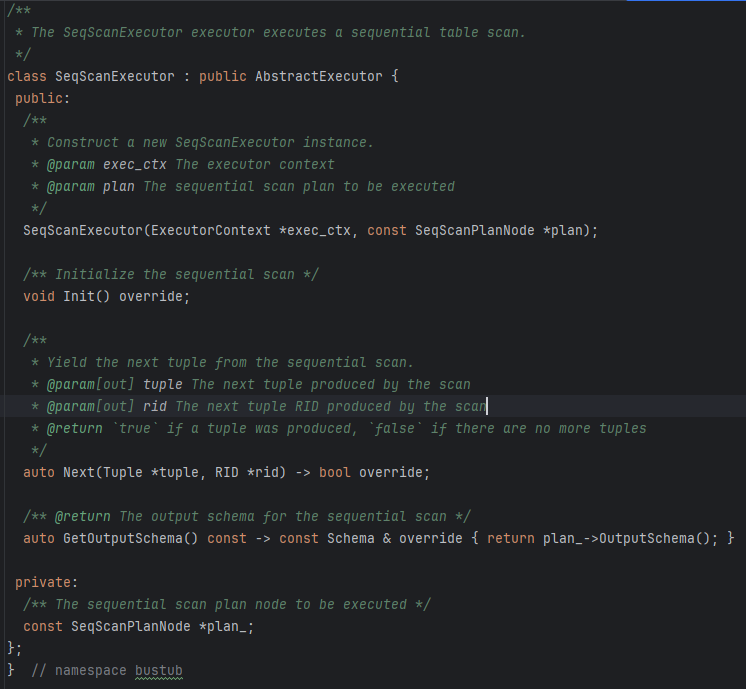
首先我们需要注意的是,SeqScanExecutor这个类继承了一个父类叫AbstractExecutor,这是所有Executor的父类,里面只有一个成员变量,ExecutorContext *exec_ctx_,这就涉及到什么是ExecutorContext.
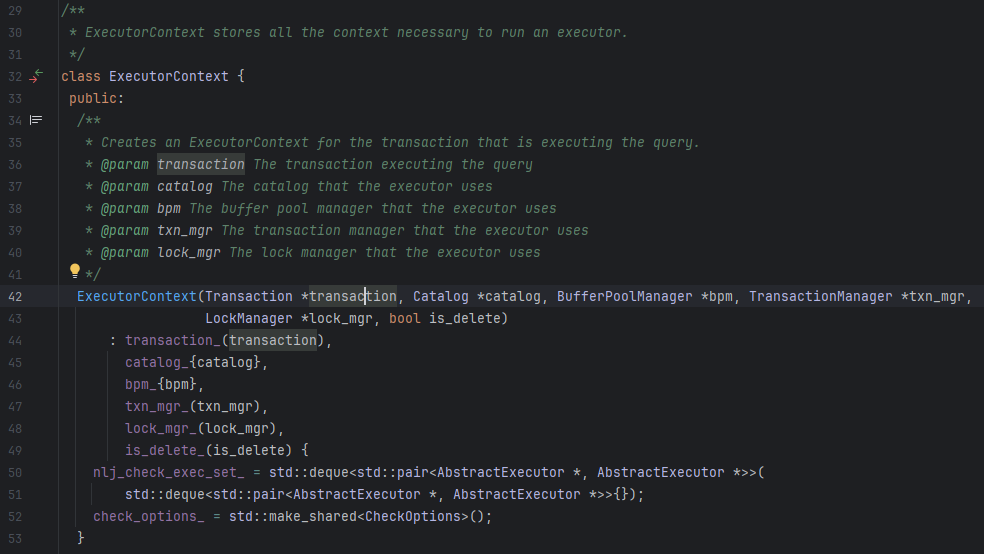
ExecutorContext stores all the context necessary to run an executor.
ExecutorContext封装了执行器运行时的上下文 -- 所有的组件和状态,包括当前查询的transaction,当前查询的catalog(上面整体图中的部分),buffer pool, transtion manager, lock manager ...
比如后续我们想要拿到所有的表,索引,就需要从executor context中拿到catalog
然后对于SeqscanExecutor来说,源码给的就只有一个成员变量,const SeqScanPlanNode *plan_; -- The sequential scan plan node to be executed. 这是顺序扫描计划节点,我们深入到SeqScanPlanNode去看一下
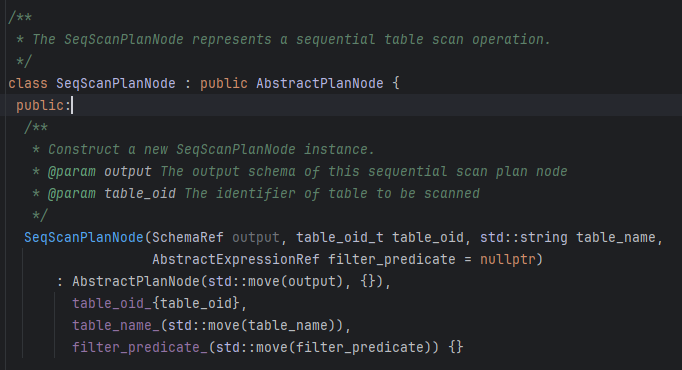
SeqScanPlanNode来源于AbstractPlanNode, SeqScanPlanNode描述了扫描计划的一些信息,比如扫描的是哪张表,输入的schema,是否有筛选条件等 -- 这个筛选条件很重要,下面用到了
我们可以去bustub-shell去看一下面语句的执行计划
CREATE TABLE t1(v1 INT, v2 VARCHAR(100));
EXPLAIN SELECT * FROM t1 WHERE v1 < 13;
EXPLAIN SELECT v2 FROM t1 WHERE v1 < 13;
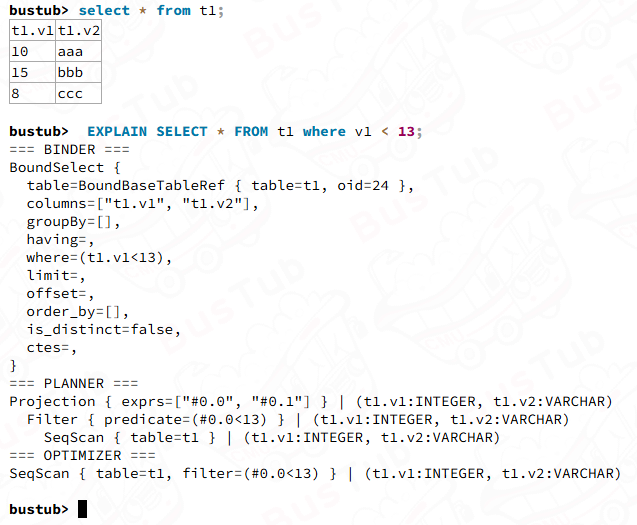
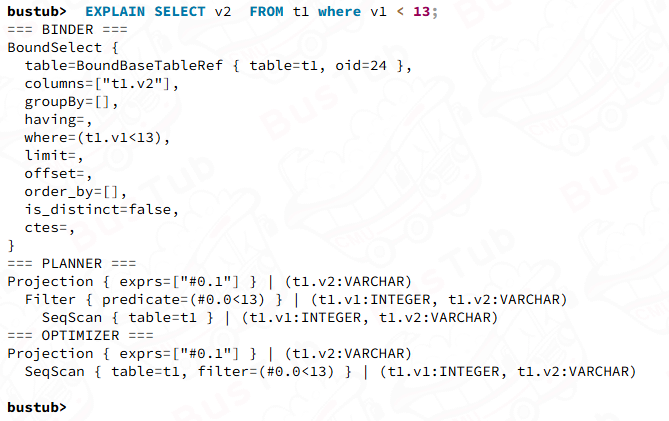
我们能看到SeqScan已经是底层的executor了,没有child executor的存在; 然后你会发现在PLANNER中的Filter最终被优化进了OPTIMIZER部分的SeqScan. 这与前面提到的SeqScanPlanNode的筛选条件就对应起来了,这是一个典型的选择操作下移,所以我们实现的时候,要特意注意实现filter的能力
弄懂了这些,我们聚焦于代码的实现,首先从next()入手
/**
* Yield the next tuple from the sequential scan.
* @param[out] tuple The next tuple produced by the scan
* @param[out] rid The next tuple RID produced by the scan
* @return `true` if a tuple was produced, `false` if there are no more tuples
*/
auto Next(Tuple *tuple, RID *rid) -> bool override
从注释中我们能发现next()返回一个生成的tuple, 不过要注意这个tuple是从参数中返回的... 其实根据init() 和 next() 包括源码注释给的描述 以及 文档中写到的iter++的问题,其实我们能想到C++和Java中的迭代器模式
Iterator<T> it = list.iterator();
while (it.hasNext()) {
T value = it.next();
}
auto it = container.begin();
while (it != container.end()) {
auto val = *it;
++it;
}
所以我们最终我是给SeqScanExecutor类加了两个成员变量
TableHeap *table_heap_;
std::unique_ptr<TableIterator> iterator_;
- 其中table heap其实就是为了方便用的,table heap的结构我们在前面介绍整体结构的时候介绍过了
- iterator是一个迭代器的指针,这里我们用的是C++11特性的智能指针,所谓智能指针就是通过RAII机制,在生命周期结束后自动释放空间
在init函数中 就是 初始化这个指针和table heap
SeqScanExecutor::SeqScanExecutor(ExecutorContext *exec_ctx, const SeqScanPlanNode *plan)
: AbstractExecutor(exec_ctx), plan_(plan) /*, table_heap_(nullptr), iterator_(nullptr)*/ {}
void SeqScanExecutor::Init() {
table_heap_ = GetExecutorContext()->GetCatalog()->GetTable(plan_->GetTableOid())->table_.get();
iterator_ = std::make_unique<TableIterator>(table_heap_->MakeIterator());
}
table heap的初始化就是从父类的GetExecutorContext方法中拿到上下文,然后拿到其中的Catlog,然后顺着通过table id拿到table Info,在拿到其中的table heap结构
iterator智能指针的初始化是通过调用table heap的MakeIterator方法实现的
然后我们就可以在Next()函数中遍历并返回每个tuple了
auto SeqScanExecutor::Next(Tuple *tuple, RID *rid) -> bool {
while (!iterator_->IsEnd()) {
auto current_tuple_pair = iterator_->GetTuple();
auto current_tuple = current_tuple_pair.second;
auto tuple_meta = current_tuple_pair.first;
if (tuple_meta.is_deleted_) {
++(*iterator_);
continue;
}
// 谓词下移 filter提前
if (plan_->filter_predicate_ != nullptr) {
Value expr_result = plan_->filter_predicate_->Evaluate(
¤t_tuple, GetExecutorContext()->GetCatalog()->GetTable(plan_->GetTableOid())->schema_);
if (expr_result.IsNull() || !expr_result.GetAs<bool>()) {
++(*iterator_);
continue;
}
}
*tuple = current_tuple;
*rid = current_tuple.GetRid();
++(*iterator_);
return true;
}
return false;
}
要注意的是,在table存在被删除过的tuple,被删除的特征就是他的metada元数据中is deleted被设置为了true;另外需要注意的是谓词下移 filter会提前,核心在于如果有filter_predicate的话,需要用evaluate方法来计算where条件是否为真,传入的参数一个是当前的tuple,另一个是schema,用来解析当前tuple中对应filter中字段的位置, 类型等
Insert
同样我们先看查询计划
-- 前面的t1表
-- CREATE TABLE t1(v1 INT, v2 VARCHAR(100));
INSERT INTO t1 VALUES (1,'aaa'), (2,'bbb');
EXPLAIN INSERT INTO t1 VALUES (1,'aaa'), (2,'bbb');
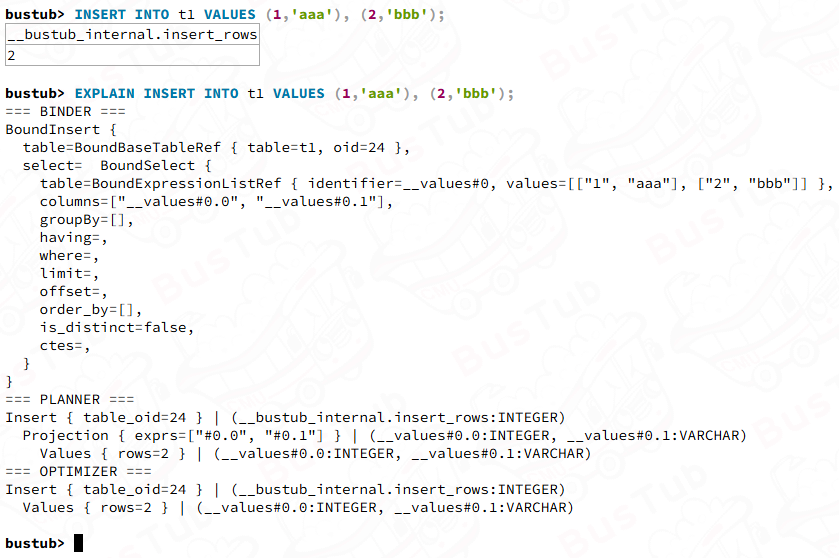
值得注意的是InsertExecutor是有ChildExecutor的,这个child的类型是ValueExecutor
但是你要注意官方给的源码的childExecutor直接就是用的AbstractExecutor,这是面向接口编程,这样的好处是,只要实现了AbstractExecutor子类的接口,比如后面我们会调用AbstractExecutor的init的,但这其实是个抽象方法,所以只要传进来的是AbstractExecutor的子类并实现了init,这里其实调用的就是子类的init
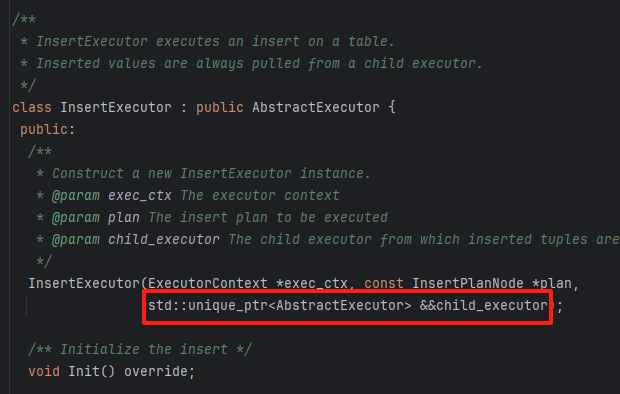
当然这里可以传入不一样的exector,但是其实在我们的例子中很明确,这里的child就是valueExecutor
所以我们在用到init和next的时候可以直接去看valueExecutor的init和next
另一个需要注意的点是InsertExecutor的返回是插入的行数,当然要注意这说到底还是个tuple,所以要把这个tuple构造出来
第三个需要注意的点是,我们插入数据的时候,同时要维护好我们的index
我们需要加入两个成员变量
std::unique_ptr<AbstractExecutor> child_executor_;
bool has_insert_;
- 对于
child_executor_这是因为虽然在构造函数中源码给了他 但源码并没有给成员变量 - has insert: 这个是用于Next()返回false的,因为上层需要调用Next直到返回false,我们第一次调用Next插入了几条value,同样我们需要一个标志说明已经插入完了,以应对下次上层调用Next的时候返回false
init函数很简单,就是初始化childExecutor和has insert -- 注意这里的child_executor_->Init();实际上就是ValueExecutor的init
在Next()中我们要:
维护has insert,以应对下次上层调用Next的时候返回false
维护一个count,最后组装成Tuple返回,注意我们之前的整体图中也标明了,事实上一个tuple是由两部分组成的,tableheap提供的InsertTuple方法是找一个page把tuple存进去,而那个Tuple实际上是tupleInfo,由真正的tuple(size和data/value)和tuplemeta(timestamp, is deleted)构成
我们查看ValueExecutor提供的next
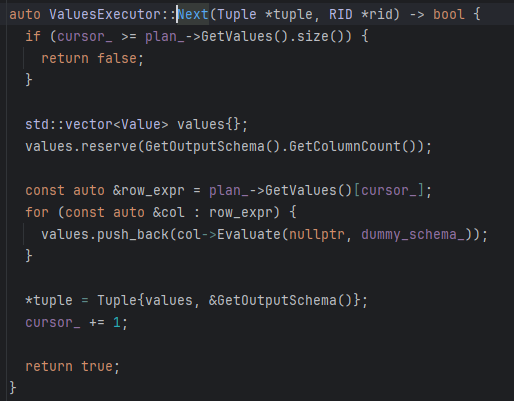
实际上你会发现ValueExecutor做的事儿就是维护了一个游标将我们VALUES (1,'aaa'), (2,'bbb') VAZLUES后面的变成了一个个tuple -- 注意并没有真正存到内存中,只是组装成了一个tuple
我们需要在InsertExecutor完成真正的存入工作,通过调用TableHeap提供的InsertTuple函数
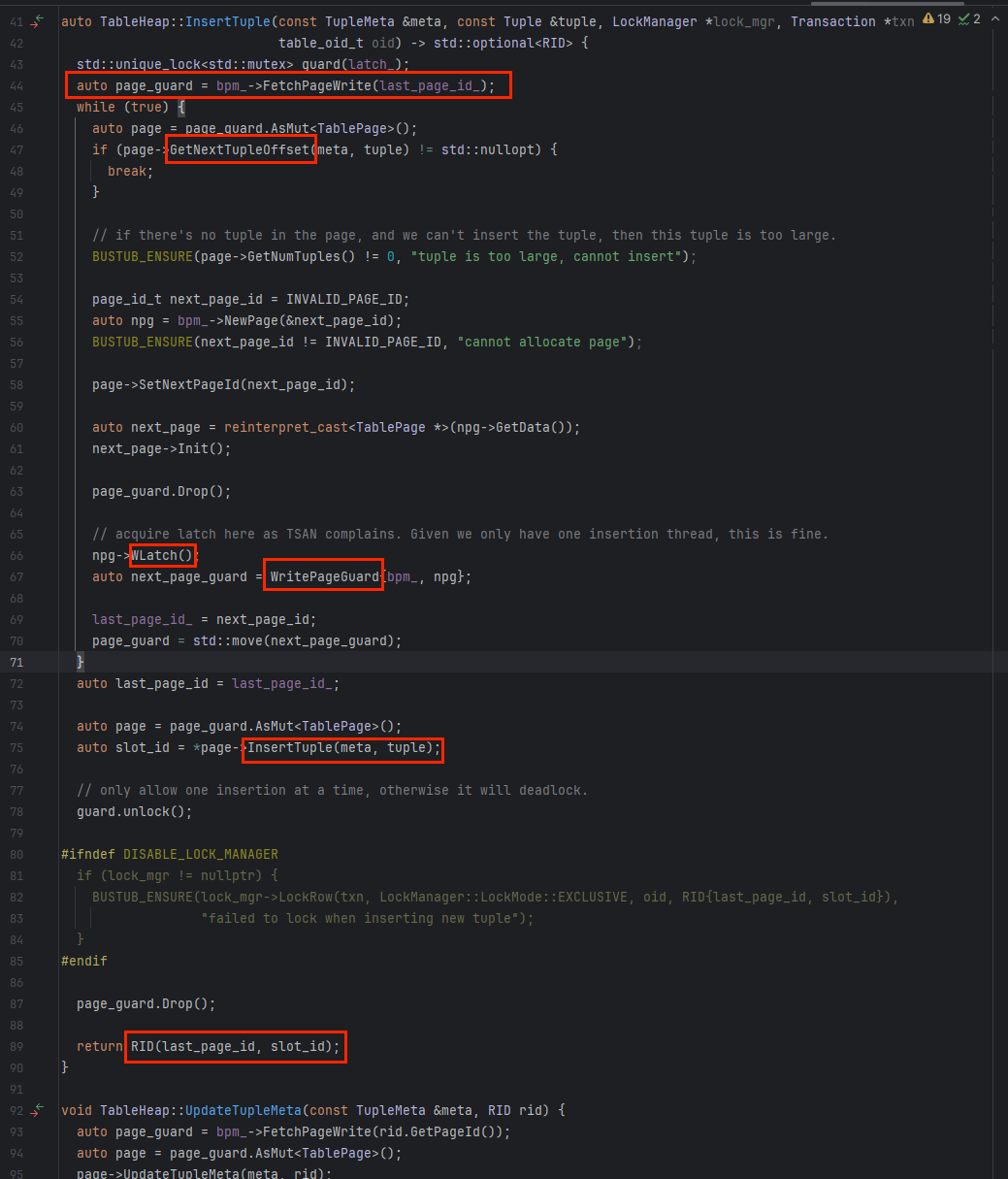
其中很多函数是我们在之前的Project中实现的,本质上这个函数是去找最后我们table heap中存的last page id,加写锁,找到能插入的slot(槽),插入tuple 。。。当然这里涉及到这个页现在到底在不在bufferpool中 需要write page guard等等 就是我们之前写的东西了
另外again, 这里插入的tuple事实上是可以叫tuple info -- tuple meta 和 tuple数据两部分(在整体图中我都标明了);RID是有两部分组成的page id和slot id(也在图中标明了)
另外我们要实现对index的维护,因为我们在2023fall中实现的是hash index -- project2写的 所以这里其实本质上就是把我们新拿到的RID要存到可扩展哈希表中
仍然是通过catlog -- 走index那条路 拿index info 找到对应的 index 而且前面我们提到了index是个抽象类,我们调用index的InsertEntry,实际上我们在本项目中调用的是ExtendibleHashTableIndex中的InsertEntry函数

而本质上ExtendibleHashTableIndex就是维护了一个可扩展哈希表(DiskExtendibleHashTable) 也就是container 而DiskExtendibleHashTable就是我们在Project2 实现的代码
本质上就是就对key进行hash 根据hash值的高位和低位分到不同的桶中
InsertExecutor Next整体代码
auto InsertExecutor::Next(Tuple *tuple, RID *rid) -> bool {
if (has_insert_) {
return false;
}
has_insert_ = true;
int count = 0;
auto table_info = exec_ctx_->GetCatalog()->GetTable(plan_->GetTableOid());
auto table_schema = table_info->schema_;
auto index_infos = exec_ctx_->GetCatalog()->GetTableIndexes(table_info->name_);
while (child_executor_->Next(tuple, rid)) {
count++;
std::optional<RID> new_rid_optional = table_info->table_->InsertTuple(TupleMeta{0, false}, *tuple);
RID new_rid = new_rid_optional.value();
for (auto &index_info : index_infos) {
auto key = tuple->KeyFromTuple(table_schema, index_info->key_schema_, index_info->index_->GetKeyAttrs());
index_info->index_->InsertEntry(key, new_rid, exec_ctx_->GetTransaction());
}
}
std::vector<Value> result = {{TypeId::INTEGER, count}};
*tuple = Tuple(result, &GetOutputSchema());
return true;
}