Lecture 02 lecture:Data Formats & Encoding I
Overview
我们讨论的是OLAP数据库 -- 工作负载和其他系统不同 -- 指导我们如何设计数据,包括布局和辅助信息……
我们在OLAP工作负载中,主要采取的access methods是Sequential scans(顺序扫描), 采取一些列措施使得速度块,但是通常不存在B+树或skip list等有助于查找单个元组的数据结构,因为不关注单个元组,而是关注聚合,唯一关注单个元组的情况是将需要的元组组合的时候
Sequential Scan Optimization

这些方法的基本思路在CMU15445的基础课程中都提到过
- Data Encoding/Compression: 数据编码与压缩 -- 如何最小化数据表示所需占用的存储空间
- Prefetching: 预取技术,在扫描表的时候识别出即将需要的数据,并提前将其加载到内存中,以便执行引擎实际需要
- Parallelization: 并行化 -- 同时运行多个查询 or 单个查询执行多个片段和任务
- Clustering / Sorting: 聚类/排序 当查询开始请求某个范围内的数据时,由于聚类或者排序,最小化所需检索数据量
- Late Materialization: 延迟物化 -- 合并是否可以推迟到最后一刻
- Materialized Views / Result Caching: 物化视图/结果缓存 -- 识别出将反复执行基本相同的查询,保留查询结果
- Data Skipping: 提前识别出不需要的数据
- Data Parallelizaiton / Vectorization: 成批处理数据流
- Code Specialization / Compilation: 代码特化/优化: 核心观点在于当明确所处理的数据类型以及查询意图时,不需要依赖引擎或执行过程来解读查询的真正需求
本学期不讨论Prefetching和Materialized Views
This Lecture: Data Encoidng/Compression -- Data Skipping
有助于next Lecture的Vectorization query
Storage Models
重温基础课程中的内容Lecture 05 Storage Models & Compression#storage models
- Choice 1: N-arry Storage Model(NSM) - row storage
- Choice 2: Decomposition Storage Model(DSM) - column storage
- Choice 3: Hybrid Storage Model(PAX) - row gorup and column chunk
老师重新讲了一遍这三种storage model的基本思想和注意的地方
值得注意的一个地方是 DSM为了达到Fix-length Offsets会使用Dictionary Encoding来压缩数据 同时注意DSM并没有解决半结构化数据的问题
有个学生提了个问题:对于row group来说是随机的嘛 对于一个row group内的数据选取
我倒是觉着应该不是随机的,应该是做了某种聚类的
为什么PAX的元数据在footer,而不是之前我们见到的header?
因为在形成Parquet和ORC的文件的时候需要扫描加载进来的所有数据逐步写出行组,并且Parquet和ORC对于行组的大小的定义是不同的,对于Parquet来说就是要读取一定行数的row作为一个行组,然后计算完生成一些数据就顺便放到尾部了 -- 换句话说我不想现在文件开头声明一块空间用来放meta-data,然后加载完巨多行(大小很大了)算完meta-data之后写回去
值得注意的是,文件的入口是footer,读取完之后就知道需要往前回溯多少内容
Persistent Data Formats
历史: 专有数据格式 -> 开源的格式 (论文一开始就提的历史)

设计文件格式需要讨论的内容 -- 其实这些内容在论文中都提到了
- File Meta-Data
- Format Layout
- Type Systems
- Encoding Schemes
- Block Compression
- Filters
- Nested Data
An Empirical Evaluation of Columnar Storage Formats | Proceedings of the VLDB Endowment这是我们看的那篇论文 -- 是Andy老师写的 这里有个有意思的事情是当时微软也在做着同样的事情 但他们不知道 所以同时微软也发了一篇论文 A Deep Dive into Common Open Formats for Analytical DBMSs | Proceedings of the VLDB Endowment 但他们用的是不同方式 不同类型的评估 所以这两篇论文互补
但总得来说这两篇论文都是类似的事情 核心都是意识到了两种最普遍的结构Parquet ORC在现代系统中一些不适应的地方
File Meta-Data
self-contained(自描述,自包含) -- means我了解为了解读文件中字节含义所需的一切信息,都包含在文件本身中 -- 这种相反跟Postgres,MySQL的思维是不同的,在Postgres和MySQL中是存在一堆文件来跟踪,比如catalog,catalog中记录了表结构,数据类型等信息
File Meta-Data包含
- Table Schema(e.g., Thrift, Protobuf)
- Row Group Offsets / Length
- Tuple Counts / Zone Maps
Thrift和Protobuf在论文中提到过,当时是作为原因来说明随着表越宽元数据解析线性增长的现象 但当时我没有去查Thrift和Protobuf是啥 这里老师提到了
Protobuf来自于Google, Thrift来自于Meta,基本上是需要定义一个模式,类似于创建表的语句,他们有一种方式来生成该模式实际内容的二进制编码,Parquet和ORC基本上就是借助这一点将字节序列化,然后将序列化的数据嵌入到文件的元数据中 -- 最大的问题在于,如果有一个非常wide的表,如果指向了解1000列中的两三列,也必须反序列化整个字节序列
有更新版本的,比如Google有flat buffers,但是其实Parquet和ORC是10年前的了,使用Thrift和Protobuf算是他们带着的"时代的遗产"hhh
Format Layout
row gourp, column chunks.
首先注意的是 Parquet和ORC中对row group和column chunks的叫法不同(论文中提到了)
另外是,对于row group的大小的定义不同(论文中也提到了)
- Parquet: number of tuples (e.g., 1 million)
- Orc: Physical Storage Size (e.g., 250MB)
- Arrow: Number of Tuples (e.g., 1024 * 1024)
当然size和number都有优缺点,尤其是在wide-table的时候(论文中也提到了,针对实验结果)
- Parquet
- Advantage: 适合Vectorization query.
- DisAdvantage: wide-table的时候 整个row group太大了;short-table的时候zone map可能不会起到很好的作用
- ORC
- Advantage: 内存大小是固定的
- DisAdvantage: wide-table的时候 tuple太少了 不利于Vectorization query
当然有一个好的问题是 anybody tried to do a hybrid solutin where you support both?
这是本课程后面会涉及到的主题,但增加文件格式的复杂性就意味着在实际处理tuple的时候要进行预测

这是来自于Databricks的图示,展示了Parquet格式的概览
其实论文中的图也说明了 Parquet和ORC的内部结构会有一点不同,叫法也会有点不同,但本质上都是相同的
Style Systems
style Systems的设计包括Physical和Logical两部分
- Physical主要是表明了机器如何表示数据,即数据在底层的字节表示方式,一般我们用的就是二进制补码整数和IEEE-754(CSAPP的内容)
- 而Logical Types基本上是定义了我们如何从logical type映射到Physical type,比如时间戳,时间戳可能是number -- int64
论文中也提到了Parquet和ORC在Style Systems中有不同的复杂性,这决定了在上游生成文件格式数据或实际使用这些数据时需要做多少工作和解读工作
对于Parquet Types | Parquet 只提供了最基本的格式
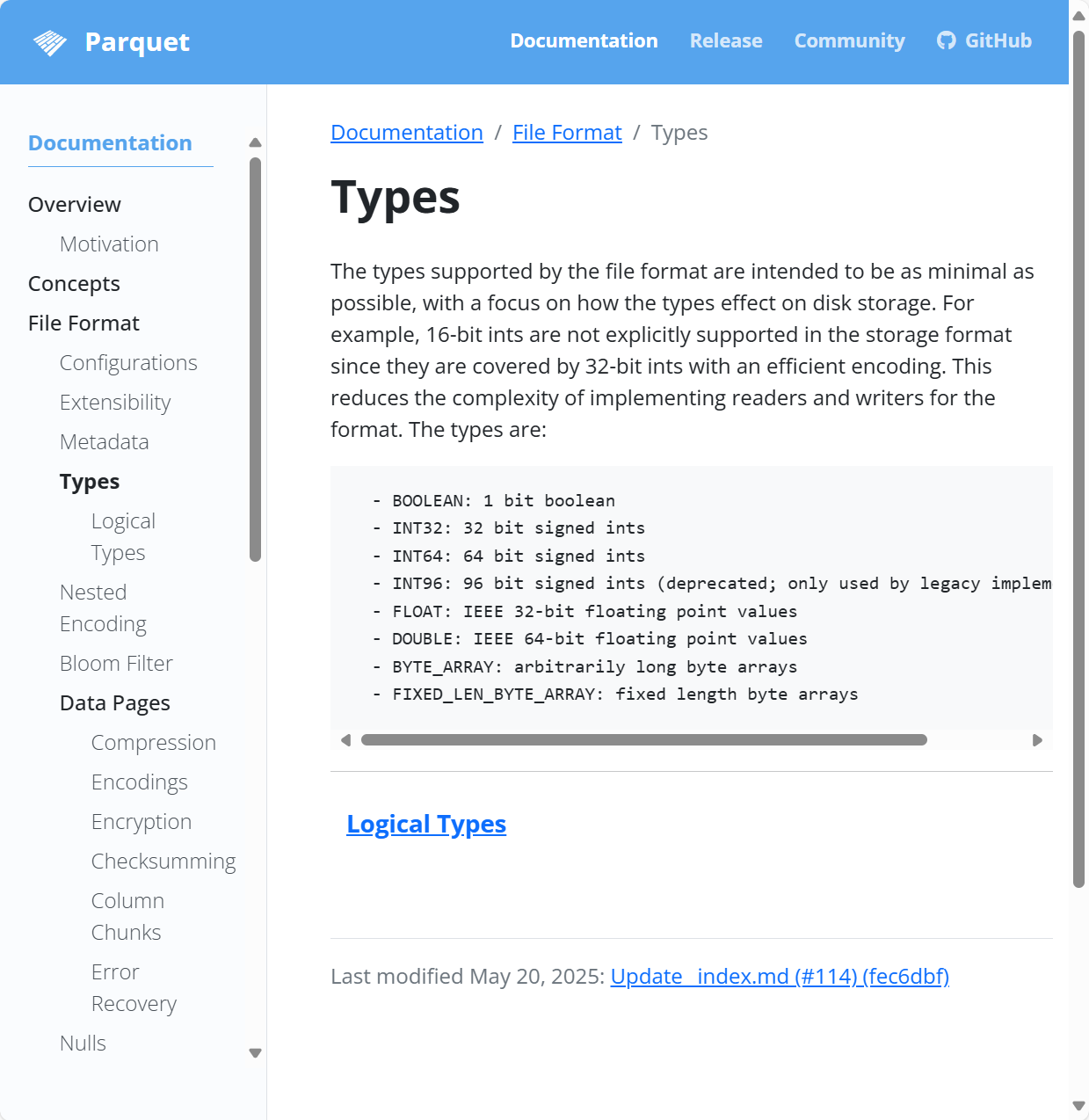
只提供int32, int64, int96, IEEE, 字节数组. 甚至连字符串都没有
还有一个有趣的点是Parquet不存储int8或者int16, 会使用bitpacking encoding
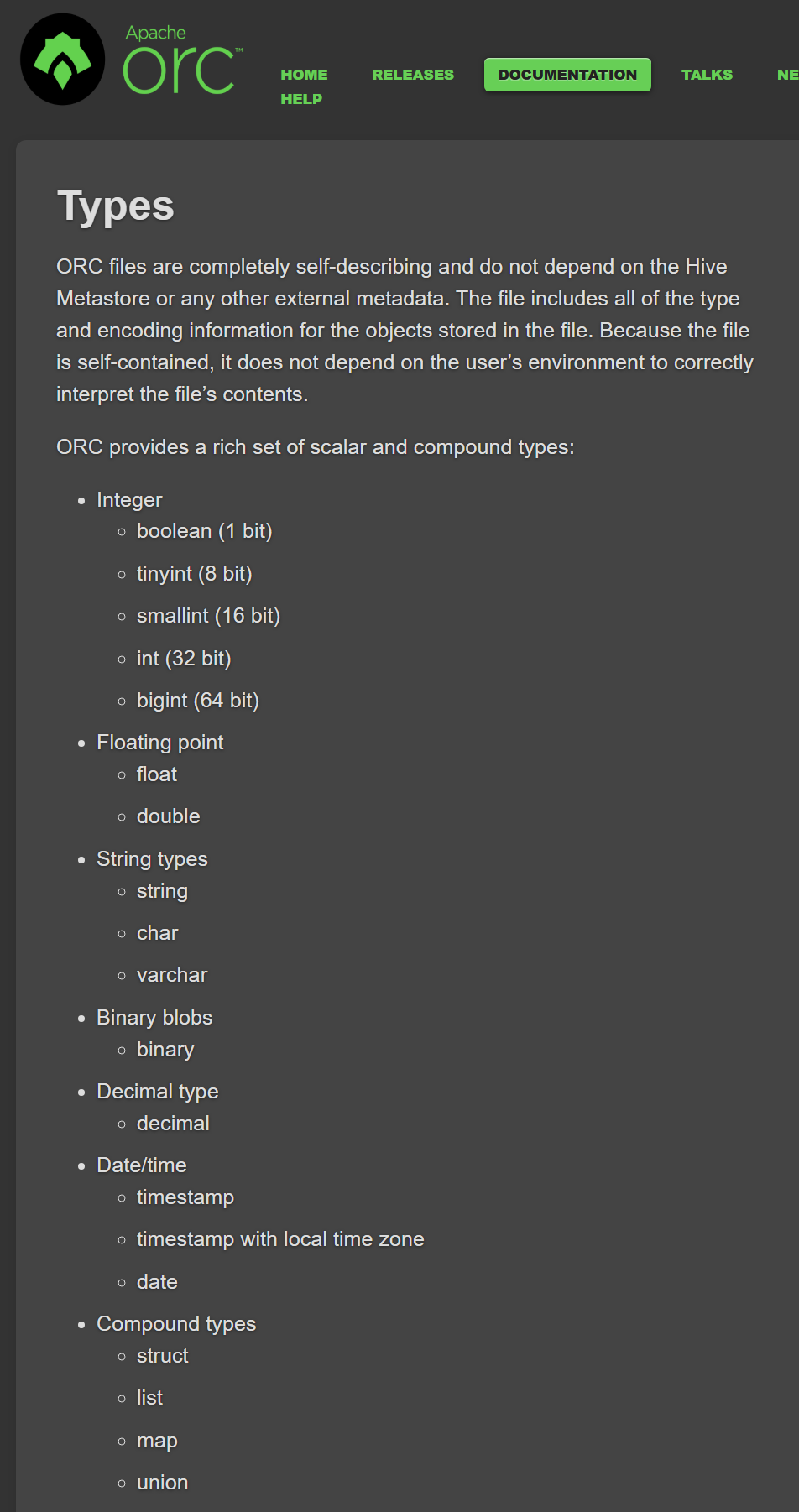
ORC的体系比较庞大
Encoding Schemes
回顾Lecture 05 Storage Models & Compression#column-level不过入门课程没提到FOR.
论文中提到的算法有
- Dictionary Encoding
- Run-Length Encoding (RLE)
- Bitpacking
- Dleta Encoding
- Frame-of-Reference (FOR)
这些算法的思想是不变的,但是在Parquet和ORC中的触发时机不同
在Lectue中着重讨论了Dictionary Encoding, 因为这是大多数数据库系统支持的最常见的编码方式
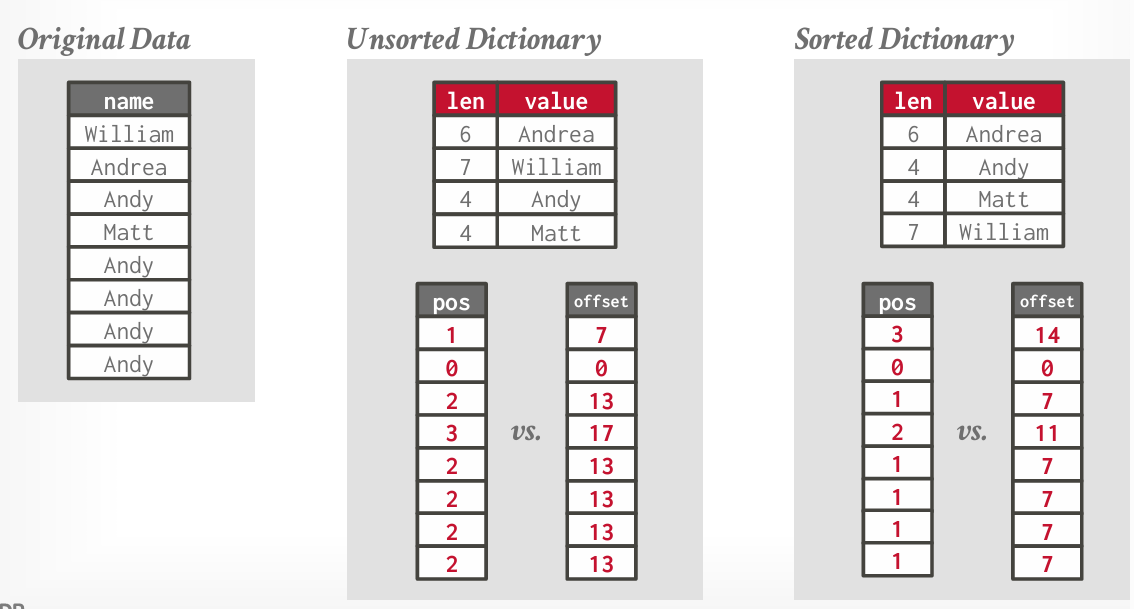
Dictionary Encoding
核心思想: 使用较小域固定长度的字典码来替换在列中频繁出现的值,然后再运行中看到字典代码,参考字典来确定实际值 -- 这是将可变长度的字符串或数据转换成固定长度值的办法
不过使用Dictionary Encoding也意味着元数据的长度变成任意长度,因为真实值会存在于字典中,而字典存储在row gourp的header
我们可以选择性的对字典中的值进行排序,编码也进行排序,来保持原始的值的增减关系,有助于在某些情况下二次压缩(这一点在论文中提到了,不过有时候是毁掉了增减关系,所以Parquet不选择后续使用FOR和Delta Encoding)
字典变大 -- 存在太多唯一值 -- 会导致失去字典编码的优势,Parquet和ORC对这个大小的阈值也是不一样的定义
- Parquet: Max dictionary size (1MB)
- ORC: NDV (number of distinct values)
这也意味着Parquet是先存 如果超过大小后续的一切数据都收到影响 都使用明文 -- 真的先存嘛? 会不会后面如果有次数多的会有替换策略换掉Dictionary中的数据?
ORC显然更直观 通过指标来衡量 因为ORC有一个前瞻缓冲区(在论文中说这是用于在贪心算法选择4中Encoding方式的),在前瞻区(maybe 512 论文中说是默认512) 进行计算
Arrow采用的是这种方式,没有构建hash table -- 无需对hash table进行序列化
Design Decision 1: Eligible Data Type
- Parquet: All data tyles
- ORC: Only things
Design Decison 2: Compress Encoded Data
- Parquet: RLE(8) + Bitpacking
- ORC: RLE(3-10), Deleta Encoding, Bitpacking, FOR
Design Decison 3: Expose Dictionary
- Parquet: Not supported
- ORC: Not supported
为什么有要提到向外开放Dictionary这个点,是因为如果开放的话可以先查阅字典,再去数据库查字典码 如果我们能“公开这个字典(Expose Dictionary)”给查询引擎使用,而不需要读取所有行数据,那么查询引擎可以 提前只看字典内容 来做决定 比如 WHERE country = 'China' → 查询引擎先查字典中有没有 'China' → 有,对应字典码是 2 → 只在编码列中查是否有 2 出现,所以不公开意味着无法将谓词下推至文件的最低层级

不过有论文做了这一点
Block Compression

we should consider 是否真的愿意承担解压缩数据块带来的计算开销。首先我们已经进行了一次Encoding压缩,虽然Block Compression仍然能得到一点收益,但是会大打折扣,而且这些方案是不透明的方案,这意味着压缩后的数据对数据库系统来说,Snappy和ZStandard压缩所输出的字节流毫无意义,它无法解读这些字节代表的含义,它无法通过它们跳转到任意偏移量,要找到查找的数据,必须压缩整个块
Block Compression在2013,2012的时候是有道理的,因为磁盘慢,网速也慢,需要减少IO传输
Filters
Parquet和ORC所拥有的过滤器只有两种: Zone Maps, Bloom Filters
zone maps复习Lecture 12 Query Execution Part 1
Bloom Filters复习Lecture 07 Hash Tables#chained hashing
这里有一个点,虽然ORC叫page index,但是索引和过滤器是有区别的
- index 索引指示了某事物的位置及其是否存在
- filters 过滤器只指示了这个数据范围内可能存在 -- 会有判断错的可能
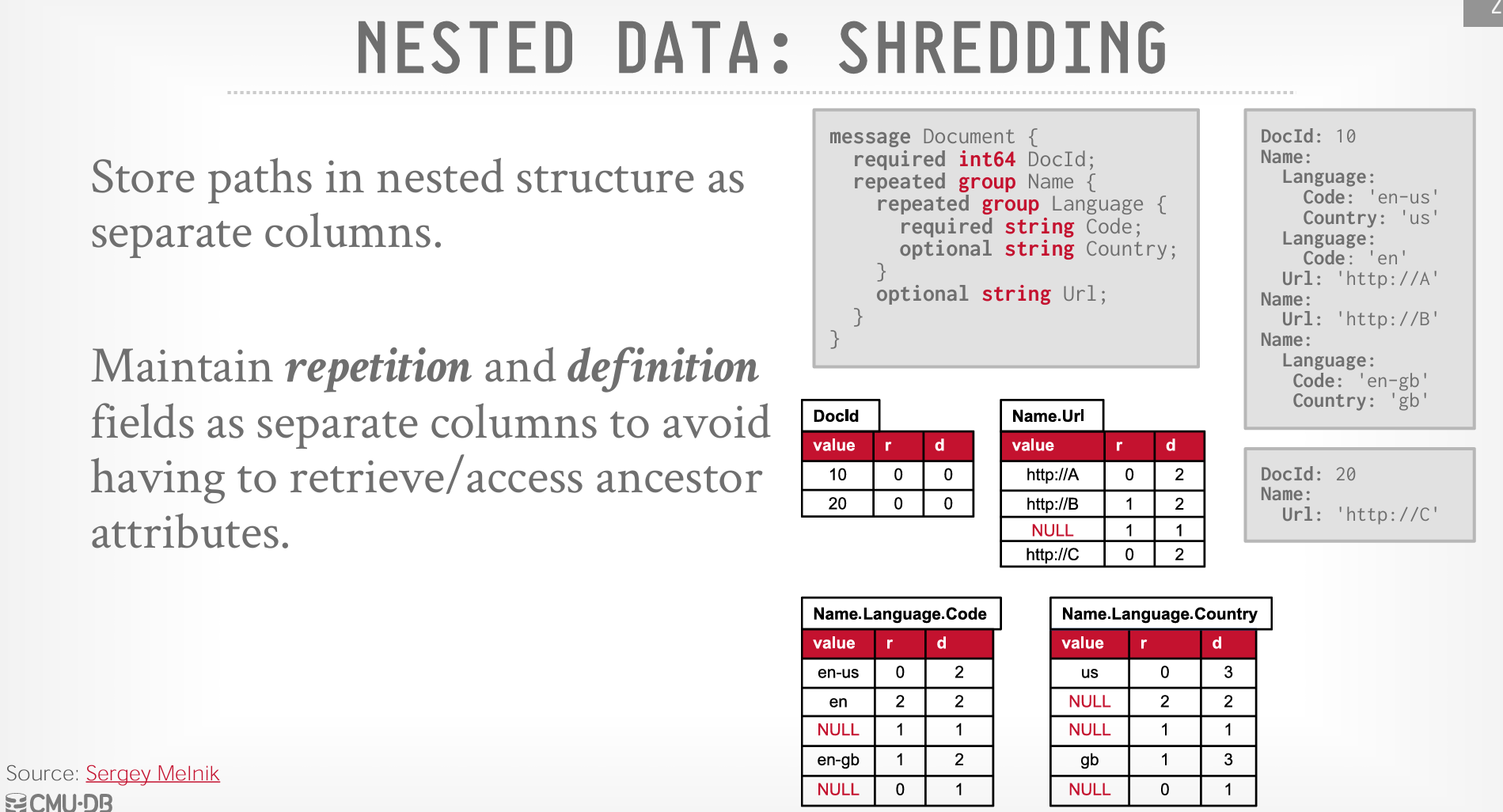
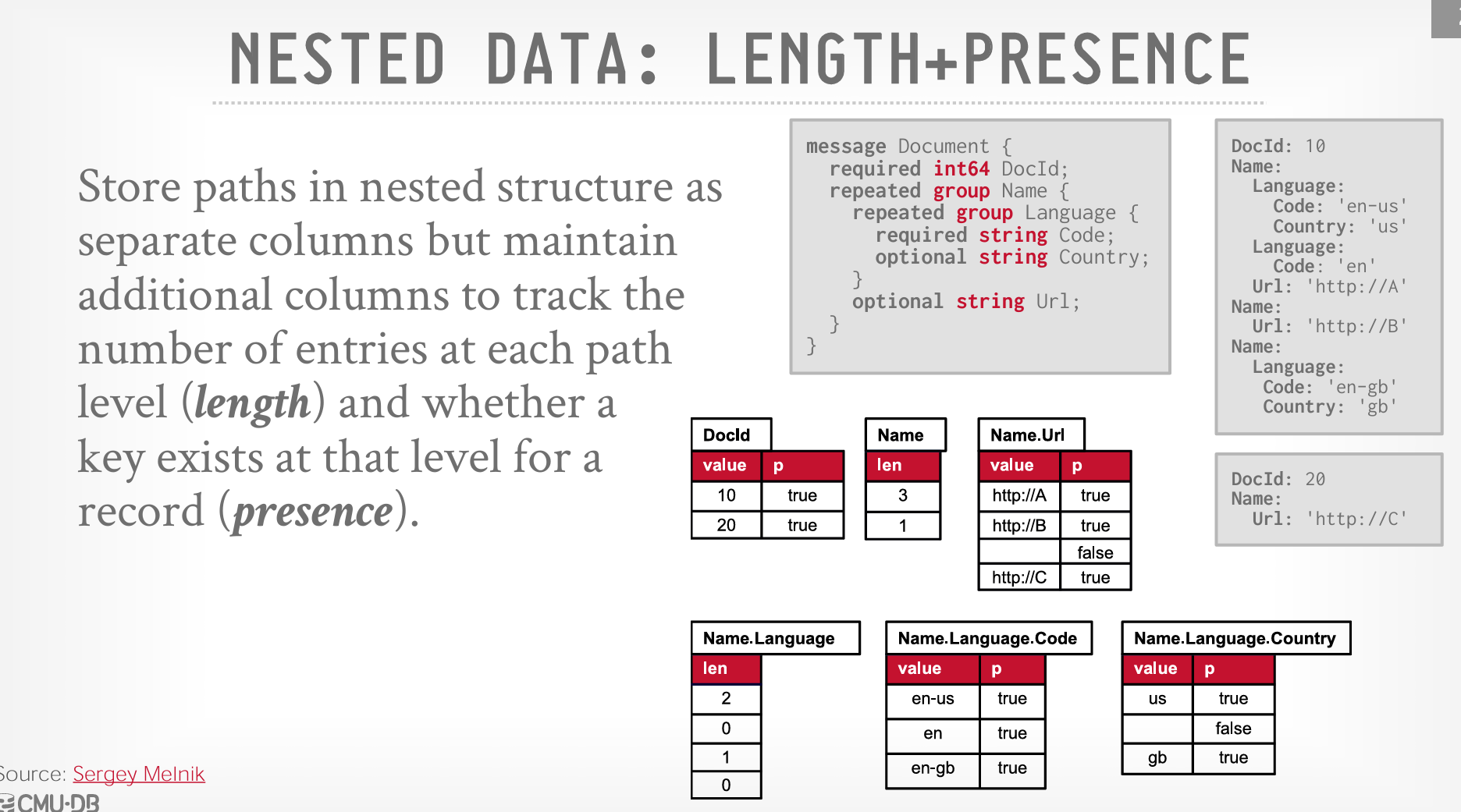
Nested Data