Lecture 05 并发控制:互斥
回教室上课了哎
today's agenda:如何正确的在多处理机上实现互斥
- 自旋锁
- 互斥锁
共享内存上的互斥
回顾互斥算法
我们其实是想要实现一个lock()和unlock()的函数 如果某个线程持有锁,则其他线程的lock不能返回
上个Lectue做了失败的尝试 和 部分成功的尝试(就是最后那个peterson算法)
-> 实现互斥的根本困难,其实就是不能同时读写共享内存(可能会以为没有同时读写,但是因为不能保证原子性,编译器或者CPU还是共享了内存)
解决问题的两种办法
- 提出算法
- 硬件来凑 : 比如加一条指令 让所有的同学(假设每个同学是一个线程)闭眼不能动手,然后只有一个同学去行动
每个人的低位都是对等的 -- 每个同学都可以同时申请其他同学闭眼睛 -- 操作系统就需要一个裁决的机制 -- 有多种可能的方式
计算机确实提供了这样的机制来达到这种"瞬间完成"的效果
wget https://jyywiki.cn/pages/OS/2022/demos/sum-atomic.c
#include "thread.h"
#define N 100000000
long sum = 0;
void Tsum() {
for (int i = 0; i < N; i++) {
asm volatile("lock addq $1, %0": "+m"(sum));
}
}
int main() {
create(Tsum);
create(Tsum);
join();
printf("sum = %ld\n", sum);
}
一个原子的加法,用了一个内联汇编 但是前面有个lock
这个lock就是像让所有人闭眼 但他其实不用保证所有人都停下来 只需要保证只要所有人不碰到sum就行了
原子指令中帮助我们实现互斥最简单的一条指令 叫做exchange

这是一个最小的load和store: 先看一下,在写进去 -- 就相当于读旧的值 然后写入新的值 -- 就好像将两个东西交换了 -- 如果不是原子的话,我们无法保证在看了之后是不是有别人重新写入东西 -- 但是exchange帮我们保证了原子性
更多的原子指令见stdatomic.h https://en.cppreference.com/w/cpp/header/stdatomic.h
自旋锁
通过xchg指令实现简单的互斥

这里的思想就是 只有拿到钥匙才能上厕所,而天黑请闭眼让所有的同学闭上眼睛不要看也不要摸,通过一张纸exchange走钥匙 然后去上厕所(临界区) -- 其他的同学及时exchange也拿不到钥匙 也没法去上厕所 直到上完厕所的回来天黑请闭眼把钥匙换回去
也就是说如果硬件保证帮我们实现一点点原子性 我们的协议就会变得简单的多
如果把这个协议翻译成代码的话

这其实就是 自旋锁
所谓自旋就是一直循环等待到能拿到钥匙
可以通过之前的model-checker来证明这个的正确性
不过model-checker的假设是这个程序每次都只执行一行,不能改变执行顺序,写内存的时候会立即进入内存……
事实上原子指令提供了这种假设,处理器会保证给lock指令排除一个先后的顺序,处理器在执行lock都严格按照指令书写的顺序来执行。 处理器还会保证比如说2之前发生的所有事情都可以在3被看见
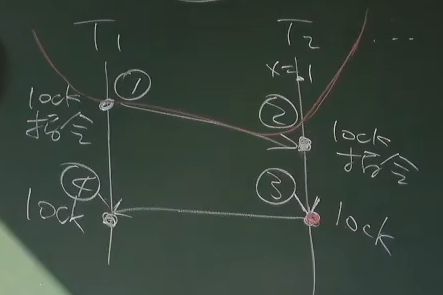
原子指令是怎么实现的? 为什么叫lock?
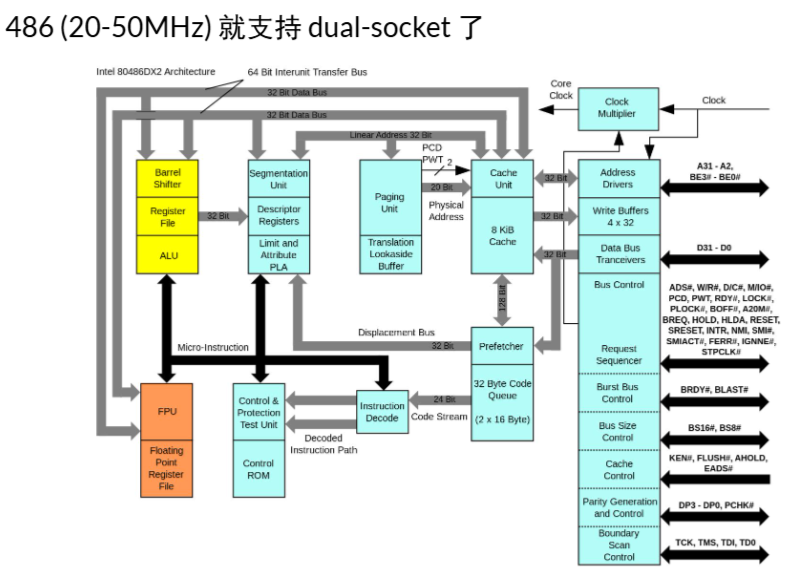
在486时代就能插两个CPU了,那么就其实有了共享内存的概念了,也有了多处理器编程了
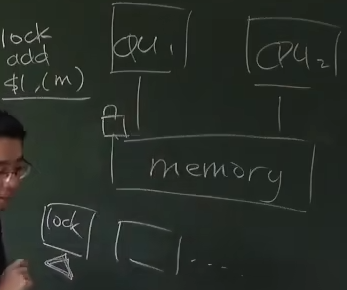
为什么会诞生lock的指令? 因为那个时候假设如果我CPU1要进行m+1的话,就会给memory加一把锁,如果两个CPU都想加锁的话由总线来决定谁先获得锁
lock前缀就像是一条指令 读到lock的时候就先去上锁
锁其实是bus lock
当然也加重了负担 x86有cache
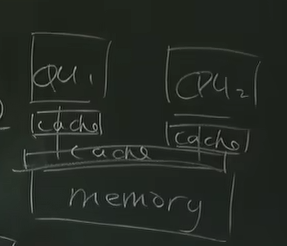
x86的结构,包括老师画的这个总的cahce 分的cache其实我们在CSAPP中见过Lecture 18 Virtual Memory:Systems#Case study Core i7/Linux memory system
缓存的一致性是一个非常大的包袱,如果两个Cache里面都有m,就需要踢出去一个

RISC-V有一个更聪明的实现方法
回顾一下常见的操作,比如前面的xchg,比如说add 本质上就是load,运算,store,这也是状态机的状态迁移所干的事儿,但在计算的时候,总会可能会有各种各样的原因(包括其他线程的操作,包括CPU的流水线,乱序都会导致可能会发生变化, 比如写入了这个地方)。所谓的原子性指令就是确保这个一读一写不会被打断
RISC-V有一个很巧的操作就是在内存上加一个标记表明我盯上你了,中断,如果其他处理器写入都会导致这个标记消除,所以只有这个标记没有被消除的时候,才会写入
这好像就是乐观锁 -- version的来源
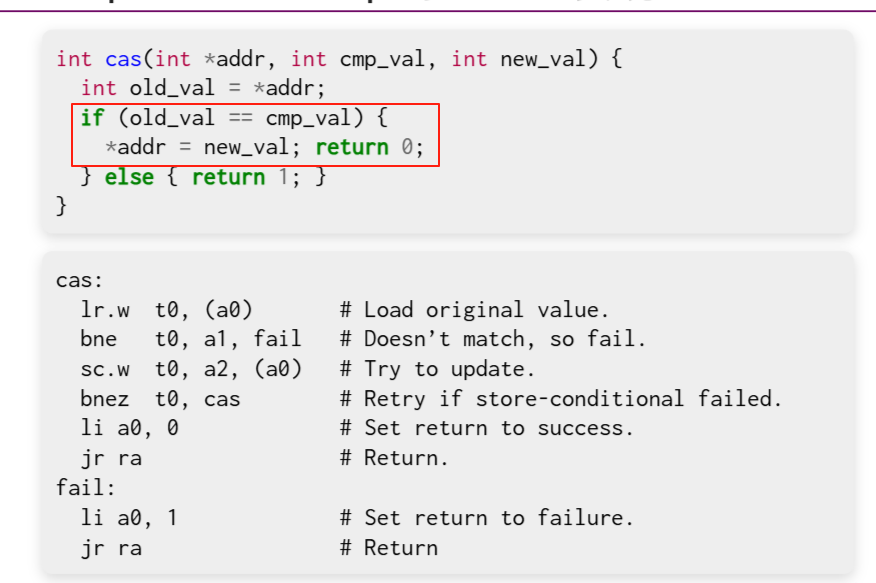
主要是多了一个判断,而不去做无谓的交换, 因为我们前面提到了说前面的例子是可以交换,但是拿到的不是钥匙,这里可以先读标记 如果有人用了 那就不用了
而且我们可以在CPU的代码中找到这段代码 https://github.com/riscv-boom/riscv-boom/blob/master/src/main/scala/lsu/dcache.scala#L655
自旋锁有什么缺陷?
得不到的钥匙的 一直在自旋
可能造成的一核出力 其他核围观
问题是如果我拿着钥匙 被OS切换走了 hh 这个线程拿着锁不运行 去睡觉了 其他线程一直在自旋 那就是没有出力的 所有核围观 出力的在睡觉hh
所以这就带出来了另一个维度 -- 除了正确性(前面提到的),还有性能
当然还有一个叫做scalability(伸缩性) -- 如果要做同一份计算任务 可能会分到多个处理器和线程上 随着CPU和线程数量的变化 运行的时间和内存会发生的变化
这里有一个例子
wget https://jyywiki.cn/pages/OS/2022/demos/sum-scalability.c
#下载自旋锁的代码
wget https://jyywiki.cn/pages/OS/2022/demos/thread-sync.h
#include "thread.h"
#include "thread-sync.h"
#define N 10000000
spinlock_t lock = SPIN_INIT();
long n, sum = 0;
void Tsum() {
for (int i = 0; i < n; i++) {
spin_lock(&lock);
sum++;
spin_unlock(&lock);
}
}
int main(int argc, char *argv[]) {
assert(argc == 2);
int nthread = atoi(argv[1]);
n = N / nthread;
for (int i = 0; i < nthread; i++) {
create(Tsum);
}
join();
assert(sum == n * nthread);
}
这个程序其实很简单,就是通过自旋锁进行sum++ 然后输入一个参数表示有多少个线程 然后把sum++这个工作摊到每一个线程上去做
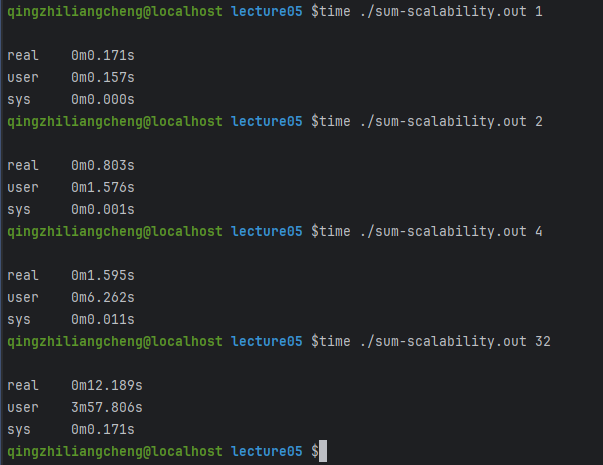
能看出来随着分摊的线程越多 会越慢 也就是所同样多的工作量,线程越多,所用的时间越多 -- 原因其实很简单 就是上面提到的自旋锁的那个原因
但是这不是很严谨,因为CPU的动态功耗,其他进程也会有影响
自旋锁的使用场景
- 几乎不拥堵
- 持有自旋锁时进制执行流切换
第二条这个 实际上应用程序是没法自己控制自己不被切换出去的
所以自旋锁真正的应用场景是 操作系统内核的并发数据结构 -- 因为操作系统可以自己决定第二条
互斥锁
如果希望实现一个线程+长临界区的互斥 怎么办
与其干等着OS的作业发布(自旋等待让出锁),不如自己(CPU)去写别的作业(线程)
对Linux来说,想要实现长临界区的互斥很简单,加一个系统调用,这时候就进入操作系统了,操作系统 内核可以把你中断关了 然后试图去获取这个锁 如果拿不到 就先把你安排去做别的事情

这里的核心思想是把你放到等待队列排着队 然后就把你安排去干别的事儿去了
这就是互斥锁
Futex = Spin + Mutex
- 自旋锁
- 更快的fast path: xchg成功 立即进入临界区 开销很小
- 更慢的slow path: xchg失败 自旋等待 浪费
- 互斥锁
- 更快的slow path: 上锁失败也不占用CPU 去干别的事情
- 更慢的fast path: 即便上锁成功也需要进出内核(syscall)
如果我们把自旋锁换成互斥锁
#include "thread.h"
#include "thread-sync.h"
#define N 10000000
mutex_t lock = MUTEX_INIT();
long n, sum = 0;
void Tsum() {
for (int i = 0; i < n; i++) {
mutex_lock(&lock);
sum++;
mutex_unlock(&lock);
}
}
int main(int argc, char *argv[]) {
assert(argc == 2);
int nthread = atoi(argv[1]);
n = N / nthread;
for (int i = 0; i < nthread; i++) {
create(Tsum);
}
join();
assert(sum == n * nthread);
}
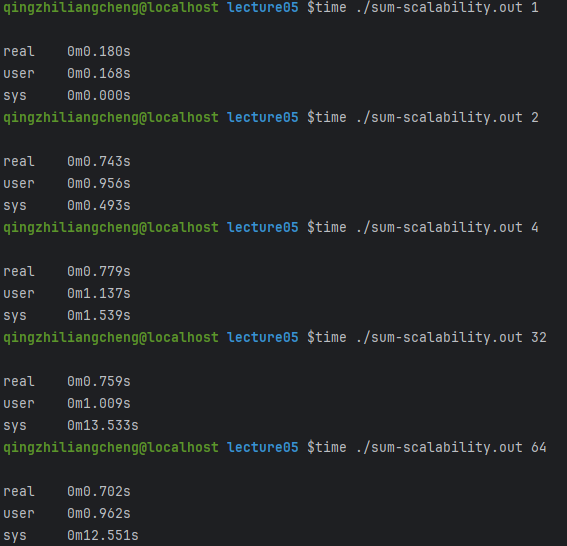
虽然一开始满了一点点 但是在32 64的时候效果很好
Futex: 都要!小孩子才做选择
突然想到2PL 二阶段锁 ??
反正这里的思想是如果上锁成功立即返回,如果上锁失败就进系统调用 进入等待队列睡一会儿 然后其他的线程可能会把他唤醒
我们在算法课上看的都是worst case,用平衡树来将最差的时间复杂度从
strace -f ./sum-scalability.out 64
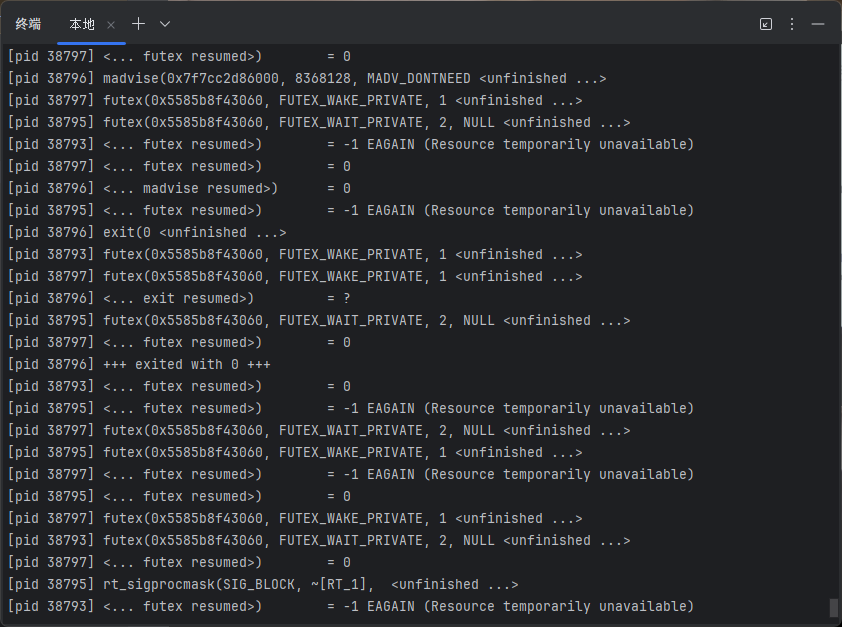
能看到好多futex